

DocArray 是一个用于传输中**嵌套的、非结构化的、多模态数据**(包括文本、图像、音频、视频、3D 网格等)的库。它使深度学习工程师能够使用 Pythonic API 高效地处理、嵌入、搜索、存储、推荐和传输多模态数据。从 2022 年 11 月开始,DocArray 成为开源项目,并由 Linux 基金会 AI 与数据倡议组织托管,以便为构建和支持开放 AI 和数据社区提供一个中立的家园。这是 DocArray 新的一天的开始。
自 DocArray 首次发布以来的十个月里,Jina AI 的开发者们看到越来越多的开源社区采用和贡献。如今,DocArray 为数百个多模态 AI 应用提供支持。
与 Linux 基金会共同托管一个开源项目
与 Linux 基金会共同托管一个项目遵循开放治理原则,这意味着没有一家公司或个人控制一个项目。当一个开源项目的维护者决定将其托管在 Linux 基金会时,他们会将该项目的商标所有权专门转让给 Linux 基金会。
在本文中,我将回顾 DocArray 的历史和未来。特别是,我将演示一些已经在开发中的酷炫功能。
DocArray 简史
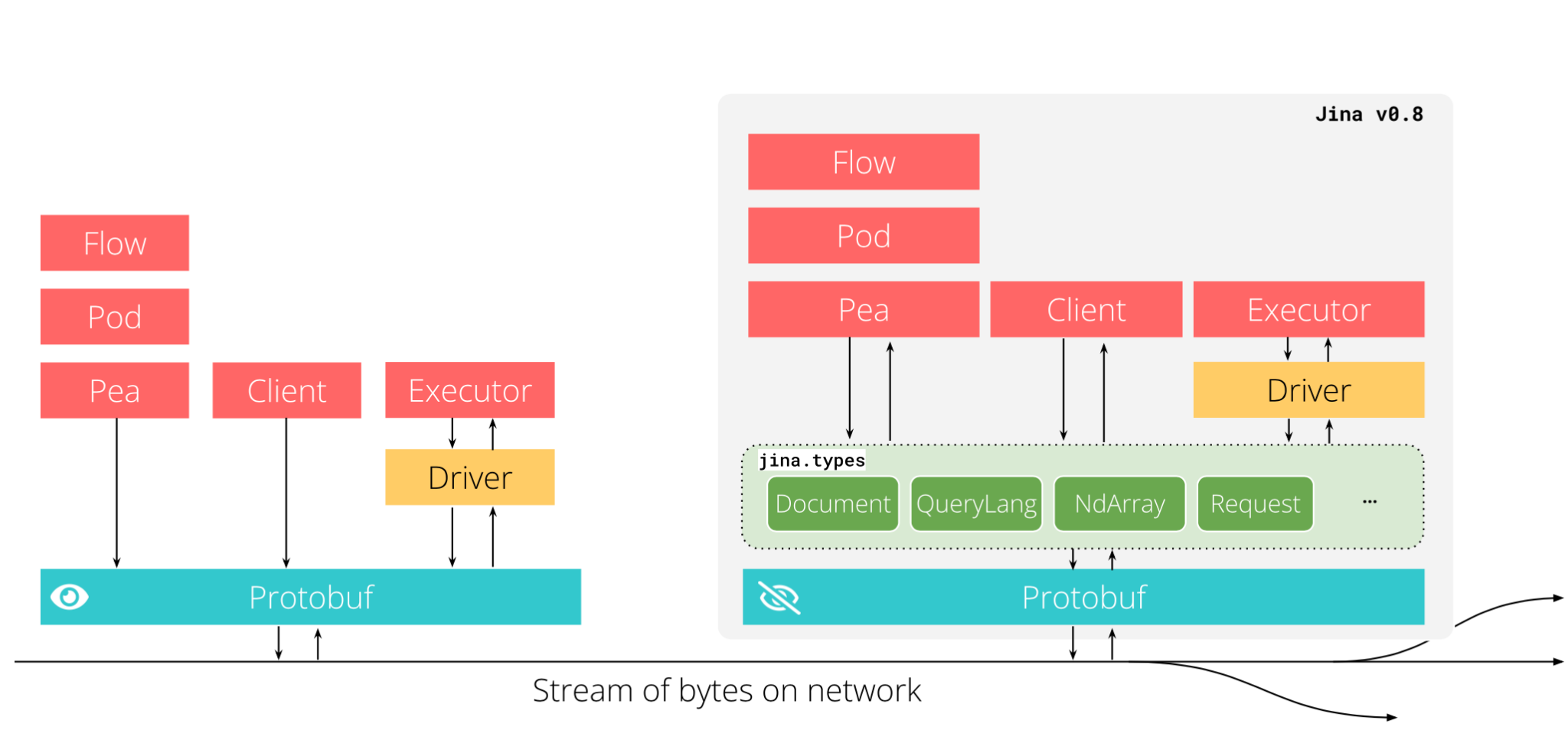
Jina AI 在 2020 年末的 Jina 0.8 中引入了 “DocArray” 的概念。它是 jina.types 模块,旨在通过明确 Jina 中的低级别数据表示来完善神经搜索设计模式。新的 Document 类没有直接使用 Protobuf,而是提供了一个更简单、更安全的高级 API 来表示多模态数据。
(Jina AI,CC BY-SA 4.0)
随着时间的推移,我们扩展了 jina.types,并超越了 Protobuf 的简单 Pythonic 接口。我们添加了 DocumentArray 以简化对多个 DocumentArrays 的批量操作。然后,我们引入了针对不同数据模态(如文本、图像、视频、音频和 3D 网格)的 IO 和预处理功能。Executor 类开始使用 DocumentArray 作为输入和输出。在 Jina 2.0(于 2021 年中期发布)中,设计变得更加强大。Document、Executor 和 Flow 成为 Jina 的三个基本概念
• Document 是 Jina 中的数据 IO
• Executor 定义了处理 Documents 的逻辑
• Flow 将 Executors 组合在一起以完成任务。
社区喜欢这种新设计,因为它通过隐藏不必要的复杂性,极大地改善了开发者体验。这使开发者能够专注于真正重要的事情。
(Jina AI,CC BY-SA 4.0)
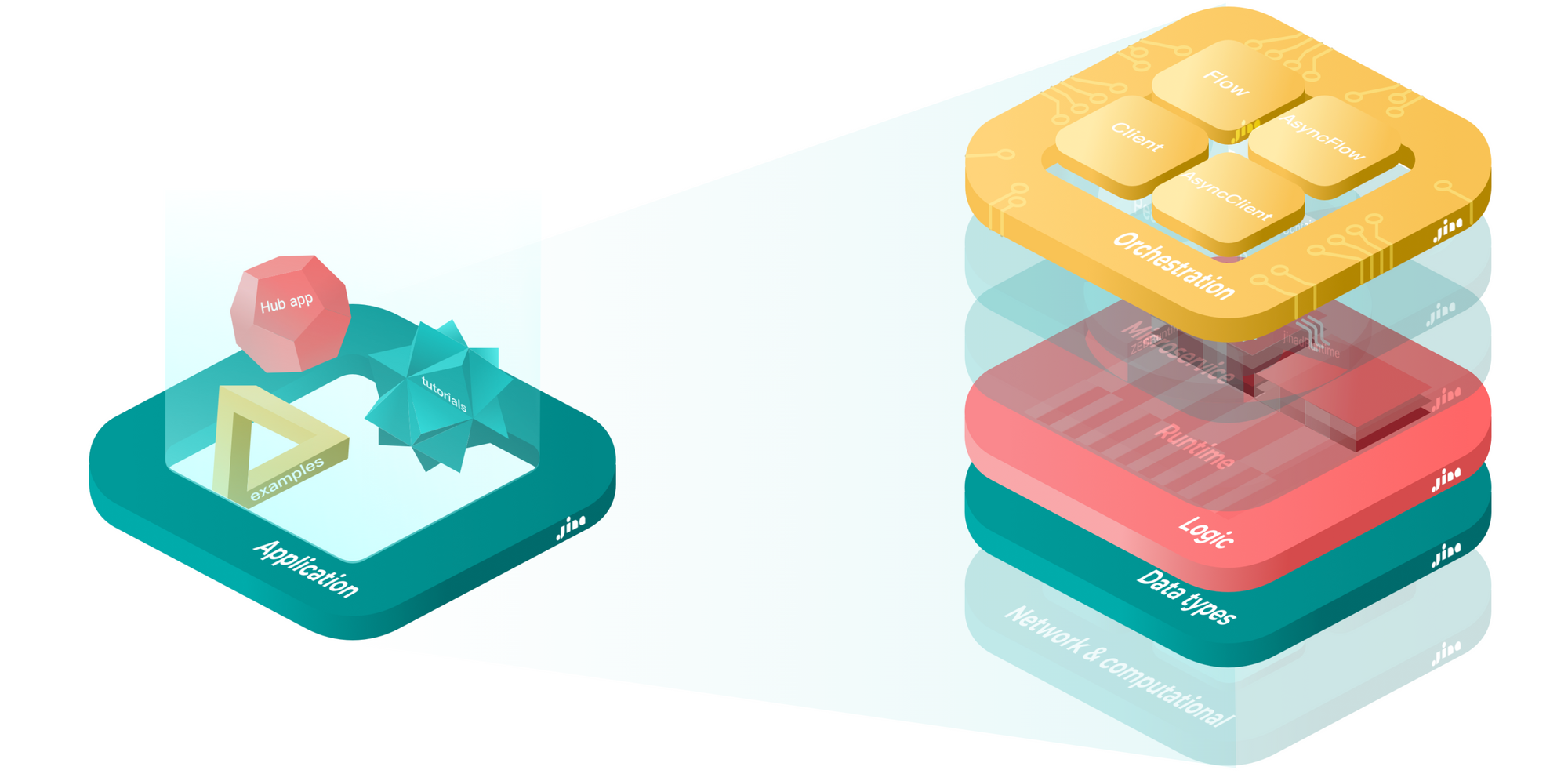
随着 jina.types 的增长,它在概念上变得独立于 Jina。虽然 jina.types 更侧重于本地构建,但 Jina 的其余部分则专注于服务化。在一个代码库中尝试实现两个截然不同的目标造成了维护障碍。一方面,jina.types 必须快速发展,并不断添加功能以满足快速发展的 AI 社区的需求。另一方面,Jina 本身必须保持稳定和健壮,因为它充当基础设施。结果呢?开发速度减慢。
我们在 2021 年末通过将 jina.types 从 Jina 中解耦来解决了这个问题。这种重构成为了后来 DocArray 的基础。那时,DocArray 的使命在团队中明确起来:为 AI 工程师提供一种数据结构,以便轻松表示、存储、传输和嵌入多模态数据。DocArray 专注于本地开发者体验,并针对快速原型设计进行了优化。Jina 扩展规模,并将原型提升为生产中的服务。考虑到这一点,Jina AI 在 2022 年初与 Jina 3.0 并行发布了 DocArray 0.1,作为一个新的独立开源项目。
我们选择 DocArray 这个名称是因为我们想使其像 NumPy 的 ndarray 一样基础和广泛使用。如今,DocArray 是许多多模态 AI 应用的入口点,例如流行的 DALLE-Flow 和 DiscoArt。DocArray 开发者引入了新的强大功能,例如 dataclass 和 document store,以进一步提高可用性。DocArray 已与 Weaviate、Qdrant、Redis、FastAPI、pydantic 和 Jupyter 等开源合作伙伴结盟,以进行集成,最重要的是寻求通用标准。
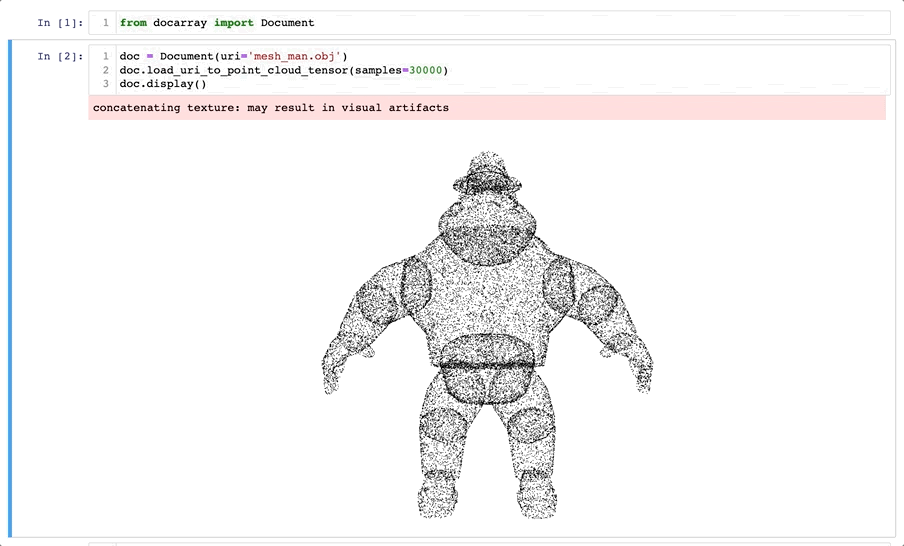
在 DocArray 0.19(于 11 月 15 日发布)中,您可以轻松地表示和处理 3D 网格数据。
(Jina AI,CC BY-SA 4.0)
DocArray 的未来
将 DocArray 捐赠给 Linux 基金会标志着一个重要的里程碑,我们在此公开、包容和建设性地与开源社区分享我们的承诺。
DocArray 的下一个版本侧重于四个任务
• 表示: 支持 Python 惯用法,以便轻松表示复杂的嵌套多模态数据。
• 嵌入: 为主流深度学习模型提供平滑的接口,以高效地嵌入数据。
• 存储: 支持多个向量数据库,以实现高效的持久化和近似最近邻检索。
• 传输: 允许快速(反)序列化,并成为 gRPC、HTTP 和 WebSockets 上的标准线路协议。
在以下部分中,DocArray 维护者 Sami Jaghouar 和 Johannes Messner 将为您介绍下一个版本的亮点。
全功能 dataclass
在 DocArray 中,dataclass 是用于表示多模态文档的高级 API。它遵循标准 Python dataclass 的设计和惯用法,让用户直观地表示复杂的多模态文档,并使用 DocArray 的 API 轻松处理它们。新版本使 dataclass 成为一等公民,并通过使用 pydantic V2 重构其旧实现。
如何使用 dataclass
以下是如何使用新的 dataclass。首先,您应该知道 Document 是一个 pydantic 模型,具有随机 ID 和 Protobuf 接口
From docarray import Document 要创建您自己的多模态数据类型,您只需从 Document 继承子类即可
from docarray import Document
from docarray.typing import Tensor
import numpy as np
class Banner(Document):
alt_text: str
image: Tensor
banner = Banner(text='DocArray is amazing', image=np.zeros((3, 224, 224)))一旦您定义了 Banner,您就可以将其用作构建块来表示更复杂的数据
class BlogPost(Document):
title: str
excerpt: str
banner: Banner
tags: List[str]
content: str向 BlogPost 添加嵌入字段很容易。您可以使用预定义的 Document 模型 Text 和 Image,它们都内置了嵌入字段
from typing import Optional
from docarray.typing import Embedding
class Image(Document):
src: str
embedding: Optional[Embedding]
class Text(Document):
content: str
embedding: Optional[Embedding]
然后您可以表示您的 BlogPost
class Banner(Document):
alt_text: str
image: Image
class BlogPost(Document):
title: Text
excerpt: Text
banner: Banner
tags: List[str]
content: Text这为您的多模态 BlogPost 提供了四个嵌入表示:title、excerpt、content 和 banner。
Milvus 支持
Milvus 是一个开源向量数据库,也是 Linux 基金会 AI 与数据下的一个开源项目。它高度灵活、可靠且速度极快,并支持在万亿字节规模上添加、删除、更新和近实时搜索向量。作为迈向更具包容性的 DocArray 的第一步,开发者 Johannes Messner 一直在实施 Milvus 集成。
与其他文档存储一样,您可以轻松地实例化具有 Milvus 存储的 DocumentArray
from docarray import DocumentArray
da = DocumentArray(storage='milvus', config={'n_dim': 10})在这里,config 是新 Milvus 集合的配置,n_dim 是一个强制性字段,用于指定存储嵌入的维度。下面的代码显示了一个在 localhost 上运行的 Milvus 服务器的最小工作示例
import numpy as np
from docarray import DocumentArray
N, D = 5, 128
da = DocumentArray.empty(
N, storage='milvus', config={'n_dim': D, 'distance': 'IP'}
) # init
with da:
da.embeddings = np.random.random([N, D])
print(da.find(np.random.random(D), limit=10))要从另一台服务器访问持久化数据,您需要指定 collection_name、host 和 port。这使用户可以通过 DocArray 熟悉且统一的 API 享受 Milvus 提供的所有好处。
拥抱开放治理
“开放治理” 一词指的是项目的治理方式,即如何做出决策、如何构建项目以及谁负责什么。在开源软件的背景下,“开放治理” 意味着项目以开放和透明的方式进行治理,并且欢迎任何人参与治理。
DocArray 的开放治理具有许多好处
• DocArray 现在以民主方式运行,确保每个人都有发言权。
• DocArray 现在更易于访问且更具包容性,因为任何人都可以参与治理。
• DocArray 的质量将会更高,因为决策是在透明和开放的方式下做出的。
开发团队正在采取行动以拥抱开放治理,包括
• 创建 DocArray 技术指导委员会 (TSC) 以帮助指导项目。
• 向社区开放更多输入和反馈的开发过程。
• 使 DocArray 开发更具包容性,并欢迎新的贡献者。
加入项目
如果您对开源 AI、Python 或大数据感兴趣,那么您受邀关注 DocArray 项目的开发。如果您认为自己可以为该项目做出贡献,请加入该项目。这是一个不断壮大的社区,并且对所有人开放。
本文最初发布在 Jina AI 博客上,并已获得许可重新发布。





评论已关闭。