

我兼职做数据审计员。可以把我视为数据表的校对员,而不是散文页面的校对员。这些数据表从关系数据库导出,通常大小适中:10万到100万条记录,50到200个字段。
我从未见过没有错误的数据表。混乱性不仅限于您可能认为的重复记录、拼写和格式错误以及放置在错误字段中的数据项。我还发现
- 由于数据项中嵌入了换行符,断裂的记录分布在多行上
- 同一记录中,一个字段中的数据项与另一个字段中的数据项不一致
- 记录中包含截断的数据项,通常是因为非常长的字符串被硬塞进 50 或 100 个字符限制的字段中
- 字符编码失败产生乱码,即所谓的文字错误
- 不可见的控制字符,其中一些可能导致数据处理错误
- 替换字符和神秘的问号,由上一个未能理解数据字符编码的程序插入
清理这些问题并不难,但找到它们存在非技术障碍。第一个是每个人天生不愿意处理数据错误。在我看到表格之前,数据所有者或管理者可能已经经历了数据悲伤的五个阶段
- 我们的数据中没有错误。
- 好吧,也许有一些错误,但它们并不重要。
- 好吧,有很多错误;我们会让内部人员来处理它们。
- 我们已经开始修复一些错误,但这很耗时;我们将在迁移到新的数据库软件时进行修复。
- 在迁移到新数据库时,我们没有时间清理数据;我们可以寻求一些帮助。
第二个阻碍进展的态度是认为数据清理需要专用应用程序——要么是昂贵的专有程序,要么是优秀的开源程序 OpenRefine。为了处理专用应用程序无法解决的问题,数据管理员可能会向程序员寻求帮助——擅长 Python 或 R 的人。
但是数据审计和清理通常不需要专用应用程序。纯文本数据表已经存在了几十年,文本处理工具也是如此。打开 Bash shell,您就拥有一个工具箱,其中装有强大的文本处理器,如 grep、cut、paste、sort、uniq、tr 和 awk。它们快速、可靠且易于使用。
我所有的数据审计都在命令行上完成,并且我已将许多数据审计技巧放在了一个“食谱”网站上。我经常执行的操作会存储为函数和 shell 脚本(请参见下面的示例)。
是的,命令行方法要求要审计的数据已从数据库中导出。是的,审计结果需要在数据库中稍后编辑,或者(如果数据库允许)需要导入清理后的数据项以替换混乱的数据项。
但优点是显著的。awk 在消费级台式机或笔记本电脑上几秒钟内即可处理数百万条记录。简单的正则表达式将找到您能想到的所有数据错误。所有这些都将在数据库结构之外安全地发生:命令行审计不会影响数据库,因为它处理的是从数据库监狱中释放出来的数据。
受过 Unix 训练的读者此时会得意地微笑。他们记得多年前以这种方式在命令行上操作数据。此后发生的变化是处理能力和 RAM 大幅提升,标准命令行工具的效率也大大提高。数据审计从未如此快速或容易。现在 Microsoft Windows 10 可以运行 Bash 和 GNU/Linux 程序,Windows 用户可以体会到 Unix 和 Linux 处理混乱数据的座右铭:保持冷静并打开终端。

图片作者:Robert Mesibov,CC BY
一个例子
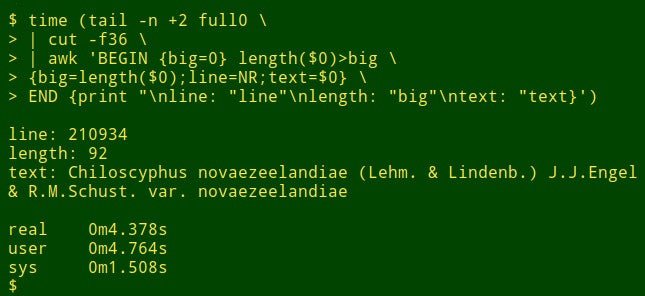
假设我想在一个大型表的特定字段中找到最长的数据项。这实际上不是数据审计任务,但它将展示 shell 工具的工作方式。为了演示目的,我将使用制表符分隔的表 full0,它有 1,122,023 条记录(加上标题行)和 49 个字段,我将在第 36 个字段中查找。(我使用我的食谱网站上解释的函数获取字段编号。)
该命令首先使用 tail 从 full0 中删除标题行。结果通过管道传递给 cut,后者提取已去除标题的第 36 个字段。管道中的下一步是 awk。在这里,变量 big 初始化为值 0;然后 awk 测试第一条记录中数据项的长度。如果长度大于 0,则 awk 将 big 重置为新长度,并将行号 (NR) 存储在变量 line 中,并将整个数据项存储在变量 text 中。然后 awk 依次处理剩余的 1,122,022 条记录,当找到更长的数据项时,重置这三个变量。最后,它打印出一个整齐分隔的列表,包含行号、数据项长度和最长数据项的完整文本。(在以下代码中,为了清晰起见,命令已分解为多行。)
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>这需要多长时间?在我的台式机上大约 4 秒(core i5,8GB 内存)
现在来说说精彩的部分:我可以将该长命令放入一个 shell 函数 longest 中,该函数以文件名 ($1) 和字段编号 ($2) 作为参数

然后我可以将该命令作为函数重新运行,在其他字段和其他文件中查找最长的数据项,而无需记住命令是如何编写的

作为最后的调整,我可以将我正在搜索的编号字段的名称添加到输出中。为此,我使用 head 提取表的标题行,将该行通过管道传递给 tr 以将制表符转换为新行,并将生成的列表通过管道传递给 tail 和 head 以打印列表中的第 $2 个字段名称,其中 $2 是字段编号参数。字段名称存储在 shell 变量 field 中,并传递给 awk 以作为内部 awk 变量 fld 打印。
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code>

请注意,如果我要在多个不同字段中查找最长的数据项,我所要做的就是按向上箭头键获取上一个 longest 命令,然后退格字段编号并输入新的编号。





评论已关闭。