

我最近决定重新审视 Football-o-Genetics,这是我在 2013 年开发的一个应用程序,旨在“进化”出接近最优的橄榄球进攻战术选择策略。该应用程序使用逐场比赛数据和来自人工智能(特别是遗传算法)和高级统计(以进攻回合的马尔可夫模型的形式)的思想来实现其目标。我在退出进化生物学博士项目后不久开发了 Football-o-Genetics,因此我选择遗传算法(我最初在 Russell 和 Norvig 的经典人工智能教科书中遇到)作为我的优化算法选择,可能并不令人惊讶。
将近四年后,我对人工智能的理解比那时更广泛和深入,现在我清楚地认识到,其他强化学习方法更适合这个问题。我认为尝试一下这些其他强化学习方法会很有趣。具体来说,我选择使用 Q 学习,这是一种学习“最优动作选择[策略]”的技术;也就是说,它可以告诉您在不同情况下采取的最佳行动,当您试图最大化某些奖励时。Q 学习是一种极其灵活和强大的技术,它是 Google 的人工智能学会以超人水平玩 Atari 游戏的关键组成部分。
Q 学习算法实际上出奇地简单实现;它只需要状态(即情况)的某种表示、可用动作的列表和奖励信号。对于战术选择问题,我选择使用三个组成部分来表示每个状态:场地位置、档数和到首攻线的距离的离散化表示(即“短”、“中”或“长”)。例如,如果球队在自己的 33 码线处,并且是二档还差 10 码,则状态编码为“33-2nd-Long”。这种编码对应于大约 100 × 3 × 3 = 900 个状态(由于我处理首攻和达阵情况的方式,实际状态更少)。(请参阅下文,了解我为何选择离散化距离。)
算法可用的动作对应于不同的战术/球员组合。两种战术是“冲球”或“传球”,每种战术都与几名球员(冲球的跑卫和传球的四分卫)之一相结合。这意味着对于任何给定状态,大约有 #跑卫 + #四分卫 = #动作 可供选择。
此时,算法已准备好进行训练。训练包括模拟进攻回合(每个回合都是强化学习术语中的“episode”)并相应地更新 Q 值。进攻回合从随机生成起始场地位置开始。然后,算法使用 ϵ-贪婪策略选择动作。选择动作后,该次战术/球员组合在当季的实际数据中采样获得的码数。这就是我选择离散化距离的原因;它使得近似特定战术/球员组合获得的码数的真实分布变得容易。更明确地说,给定的档数/距离/战术/球员组合与一个列表相关联,例如,down_and_distance["2ndMedPass"]["C Newton"] = [-2, 1, 4, 0, 0, 0, 17, 13, 11, 0, 0, 17, 0, 0, 0, 0, 3, 27, 4, 4, 5, 0, 0, -2, 0, 0, 3, 11, 1],并且在战术中获得的码数是从该列表中随机抽取的。用于训练模型的数据来自 2012 年,因为这是我为原始应用程序收集的数据。
然后,模拟像典型的橄榄球比赛一样进行,档数和距离相应更新。失误以根据当季实际失误数据估算的概率生成。当发生失误或回合到达四档时,回合终止,模拟从头开始重新启动。除了达阵之外,所有战术结果的奖励信号均为零,达阵的奖励信号为一。
opensource.com
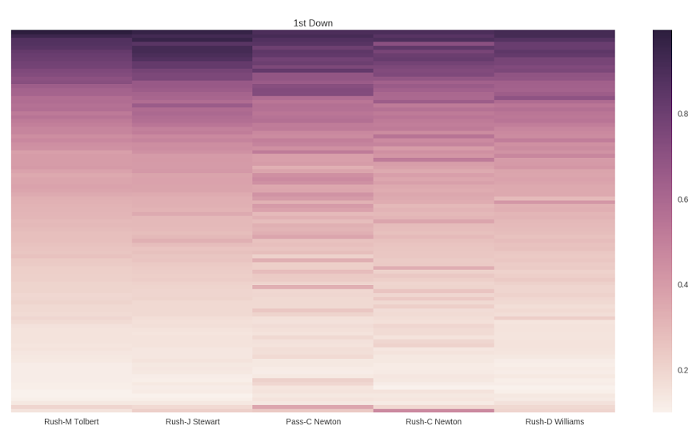
正如您在图 1 中看到的那样,您离端区越近(图的顶部),回合最终导致达阵的可能性就越大。您还可以看到,总的来说,在 2012 年,让 Cam Newton 在首攻中跑球或传球通常是黑豹队的最佳策略。
虽然这些结果很有趣,但它们实际上并不代表最佳战术选择策略,因为该模型将防守视为环境的一部分,而不是能够适应进攻趋势的对手。不幸的是,防守战术选择数据很难获得,但我已决定概述如果我有时间坐下来观看大量橄榄球比赛,我将如何处理这个问题。(人总要梦想,不是吗?)
进攻战术有一个很好的自然分类——冲球和传球——但对防守战术进行分类并不那么容易。虽然有一些信息丰富的防守战术描述符可用,例如“闪电战”或“区域”与“盯人”,但它们似乎都不能完全捕捉到防守战术的精髓。鉴于这种情况,我建议冲锋防守队员的数量可以填补这一角色。虽然您无法通过这种分类获得有关防守覆盖范围的精确信息,但它确实让您了解防守在战术中的“侵略性”,并且我怀疑这种属性将转化为有用的统计属性。例如,我预计冲锋防守队员的数量与进攻在冲球战术中获得的平均码数之间存在负相关关系。
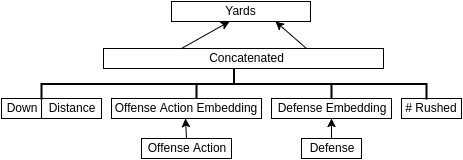
因此,在建立了防守战术选择的分类之后,下一步是确定在给定进攻战术选择和防守战术选择的情况下如何生成码数。我认为我会采取类似于我对 (击球手|投手)2vec 所做的方法,我在其中构建了一个模型,该模型通过尝试预测几个棒球赛季中每次投球的结果(例如,好球、坏球、左外野高飞球)来学习击球手和投手的分布式表示。类似的橄榄球模型,我将其称为 (进攻|防守)2vec,可能看起来像图 2。
opensource.com
此模型的输入将是档数、距离、进攻动作(例如,“传球-C Newton”)、防守球队和战术中冲锋的防守队员数量。进攻动作的数量大约等于 #球队 × (#四分卫 + #跑卫),我们估计约为 32 × (1.5 + 2.5) = 128。对于输出,执行回归似乎是显而易见的选择,但从概率的角度来看,使用均方误差优化回归模型等同于假设输出上存在高斯分布(以模型和输入为条件),并且我认为高斯分布在这里不合适。另一方面,将所有可能的码数增益(即从 -99 到 99)视为不同的类别可能是不必要地细粒度的,并且可能使学习变得嘈杂。
opensource.com
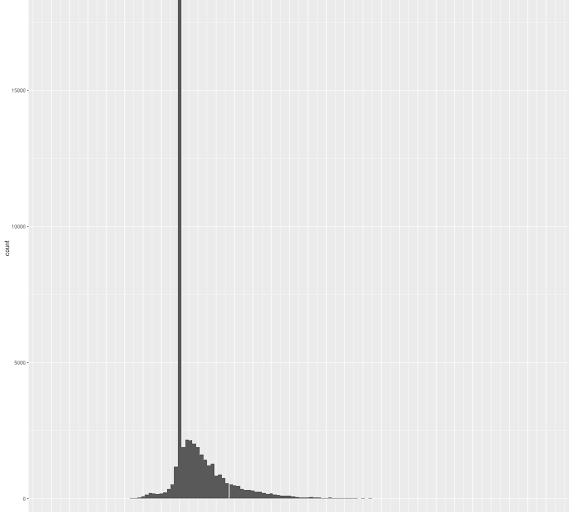
查看图 3 中的直方图(从卡内基梅隆大学发布的 2015 年 NFL 数据集生成),我认为合理的输出层可能有一个用于 100 到 40.5 码的 bin(代表分布的 1%),一个用于零码的 bin,用于 -15 到 -5.5 码和 -5.5 到 -0.5 码的 bin,以及从 0.5 开始(因此 0.5 到 2.5 将是第一个 bin)到 40.5 结束(因此最后一个 bin 是 38.5 到 40.5)的每个两码跨度的 bin。
要为给定的战术生成码数,您首先需要使用档数、距离、进攻动作、防守和冲锋防守队员数量提供的概率分布对其中一个 bin 进行采样。从那里,您将从 bin 中包含的码数中均匀采样。因此,对于范围从 18.5 到 20.5 码的 bin,您将有 50% 的机会获得 19 码,以及 50% 的机会获得 20 码。显然,您可以对这些分布进行更复杂的操作,但分箱方法似乎是合理、简单的近似值。此时,剩下的唯一事情就是实施 minimax Q 学习,然后使用新的码数生成器重新运行模拟。
无论如何,这就是所有的假设。您可以在 GitHub 上下载 Football-o-Genetics 源代码。如果您做过类似的工作,或者如果这个项目最终启发您从事自己的项目,我很乐意听到您的消息。
经 Red Hat 高级软件工程师 Michael A. Alcorn 的博客许可转载。





4 条评论