

历史学家和侦探有很多相似之处:他们的调查工作既费力又注重细节。信息片段通常是模糊的、矛盾的和复杂的。人名在不同的来源中可能有不同的拼写,尤其是在涉及多种语言的情况下。还有一个时间维度——他们需要知道每个可能的罪犯在每个特定时间点在哪里。最后,他们可能会发现杀死老妇人的不是一个园丁,而是两个。
传统上,历史学家(和侦探)将这些信息记在脑子里和笔记卡上,皱巴巴的纸片,抄书上加光的条目等等。历史研究人员开始承认,计算机可能存在足够长的时间来证明它们不是一个短命的现象(对他们来说,短期意味着 100 年或更短),而数字人文作为一个独立研究领域的出现证明了这一点。

历史语义网络的概念示例。作者:Maximilian Kalus。CC BY-NC-ND。
Segrada 是一款开源软件,允许历史学家(和侦探)跟踪他们的数据。与维基或档案数据库不同,它的重点在于信息及其内部的相互关系。信息片段可能代表人物、地点、事物或概念。这些“节点”可以双向连接,以语义方式表示友谊、血缘关系、行踪、作者身份等等。因此得名“语义图数据库”,因为信息可以显示为语义连接节点的图。
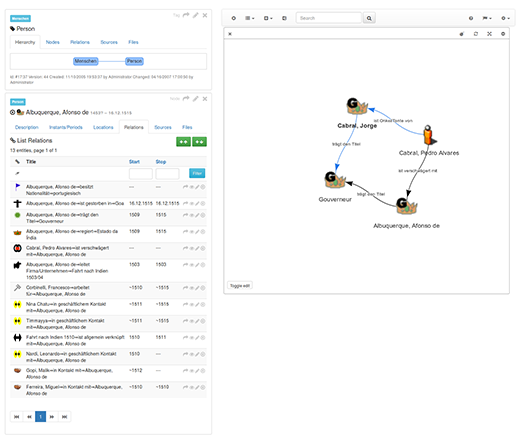
上面的图像显示了历史语义网络可能的样子。有几种不同类型的节点代表地点和人物。节点通过人类读者可以轻松掌握的图表连接。图表是双向的,这意味着它们可以双向解释。该图还描述了日期,其中一些是部分的(例如,仅年份)。Segrada 支持部分和模糊日期,以及标签和地理参考。该图未显示的是节点和关系的文本描述,或保存信息来源的来源参考。数据库支持这些功能。此外,文件可以上传到数据库中,并在需要时进行全文索引。这使得不仅可以搜索数据库内容,还可以搜索引用的文本。
Segrada 的最初目的是支持历史学家逐步拼接历史数据,以便最终构建人际网络。当前数据库的前身是作为博士论文的一部分开发的,该论文涵盖了 16 世纪葡萄牙与亚洲贸易中的德国和意大利投资者网络。在该研究过程中,创建了大约 1,400 个节点,并通过近 6,800 个关系连接起来。
虽然按照数据库标准来看这可能很小,但它显示了一个历史学家在四年多的时间里可以从各种来源中费力地拼凑出什么:记录了 1,000 多人,并且在一个庞大的网络中可以发现许多新的细节,该网络交易印度胡椒、亚洲香料、蒂罗尔和匈牙利铜、波美拉尼亚谷物和汇票(主要在里昂),由葡萄牙、德国、意大利和西班牙商人经营。上图显示了一个典型的屏幕截图,描绘了葡萄牙探险家和总督 阿方索·德·阿尔布克尔克 在研究过程中创建的网络的一部分。
Segrada 适用于任何人,而不仅仅是历史学家和侦探。它也可能被家谱学家、组织任意信息的知识工作者或试图弄清楚《权力的游戏》中关系和地点的人使用。该软件是基于 Web 的,但可以从桌面运行。除了 Java 之外,对操作系统没有其他要求。这使得普通用户可以方便地使用该软件,尽管它也可以在一个或多个服务器上运行,以便授予团队人员访问单个项目的权限。
应该注意的是,Segrada 是一个相当新的项目,仍处于测试阶段。您不必成为侦探即可加入——编码、支持、文档、测试和反馈都非常受欢迎。该项目的源代码可以在 GitHub 上找到,二进制下载可在 官方项目网站 上获得。





1 条评论