

可观测性是了解和解释部署当前状态的能力,以及了解何时出现问题的方法。随着应用程序作为微服务在 Kubernetes 和 OpenShift 上的云部署不断增长,可观测性正受到越来越多的关注。许多应用程序都带有严格的保证,例如关于停机时间、延迟和吞吐量的服务级别协议 (SLA),因此网络级可观测性是一项非常重要的功能。网络级可观测性由多种编排器提供,可以通过原生方式或使用插件和操作符来实现。
最近,eBPF(扩展的 Berkeley Packet Filter)由于其性能和灵活性,成为在终端主机内核中实现可观测性的流行选择。这种方法使自定义程序能够挂钩到网络数据路径上的某些点(例如,套接字、TC 和 XDP)。已经发布了几个基于 eBPF 的开源插件和操作符,每个插件和操作符都可以插入到终端主机节点中,以通过您的云编排器提供网络可观测性。
现有的可观测性工具
可观测性模块的核心组件是它如何以非侵入方式收集必要的数据。为此,我们使用工具化的代码和测量,研究了 eBPF 数据路径的设计如何影响可观测性模块的性能以及它正在监控的工作负载。我们的测量工件是开源的,并且可以在我们的 研究 Git 仓库中找到。我们还能够提供一些有用的见解,您可以在设计可扩展且高性能的 eBPF 监控数据路径时使用这些见解。
以下是可用于在网络和主机上下文中实现可观测性的现有开源工具
Skydive
Skydive 是一个网络拓扑和流分析器。它将探针附加到节点以收集流级别的信息。探针使用 PCAP、AF_Packet、Open vSwitch 等附加。Skydive 没有捕获整个数据包,而是使用 eBPF 来捕获流指标。附加到套接字挂钩点的 eBPF 实现使用哈希映射来存储流标头和指标(数据包、字节和方向)。
libebpfflow
Libebpfflow 是一个使用 eBPF 提供网络可见性的网络可见性库。它挂钩到主机堆栈中的各个点,例如内核探针 (inet_csk_accept、tcp_retransmit_skb) 和跟踪点 (net:netif_receive_skb、net:net_dev_queue) 以分析 TCP/UDP 流量状态、RTT 等。此外,它还提供了进程和容器映射,用于分析的流量。它的 eBPF 实现使用 perf 事件缓冲区将 TCP 状态更改事件通知给用户空间。对于 UDP,它附加到网络设备队列的跟踪点,并使用 LRU 哈希映射和 perf 事件缓冲区的组合来存储 UDP 流指标。
eBPF Exporter
Cloudflare 的 eBPF Exporter 提供了用于插入自定义 eBPF 代码以记录感兴趣的自定义指标的 API。它需要将整个 eBPF C 代码(以及挂钩点)附加到 YAML 文件以进行部署。
Pixie
Pixie 使用 bpftrace 来跟踪系统调用。它使用 TCP/UDP 状态消息来收集必要的信息,然后将其发送到 Pixie Edge Module (PEM)。在 PEM 中,数据根据检测到的协议进行解析并存储以供查询。
Inspektor
Inspektor 是 Kubernetes 集群调试工具的集合。它有助于将低级内核原语与 Kubernetes 资源进行映射。它作为守护程序集添加到集群的每个节点上,以使用 eBPF 收集诸如系统调用之类的事件的跟踪。这些事件被写入 perf 环形缓冲区。最后,当发生故障时(例如,pod 崩溃时),回顾性地使用环形缓冲区。
L3AF
L3AF 提供了一组 eBPF 包,可以使用尾调用将这些包打包并链接在一起。它提供了一个网络可观测性工具,该工具根据流 ID 将流量镜像到用户空间代理。此外,它还通过在 eBPF 数据路径中的哈希映射上存储流记录来提供 IPFIX 流导出器。
Host-INT
Host-INT 扩展了带内网络遥测支持,以支持主机网络堆栈的遥测。从根本上讲,INT 将每个数据包的交换延迟嵌入到数据包的 INT 标头中。Host-INT 对两个主机之间的主机网络堆栈执行相同的操作。Host-INT 有两个数据路径组件:基于 eBPF 的源和接收器。源在发送方主机接口的 TC 挂钩上运行,接收器在接收方主机接口的 XDP 挂钩上运行。在源处,它使用哈希映射来存储流统计信息。此外,它还在 INT 标头中添加了入口/出口端口、时间戳等。在接收器处,它使用 perf 数组在每个数据包到达时将统计信息发送到接收器用户空间程序,并将数据包发送到内核。
Falco
Falco 是一个云原生运行时安全项目。它使用 eBPF 探针监控系统调用,并在运行时解析它们。Falco 具有配置关于活动的警报的功能,例如使用特权容器的特权访问、读取和写入内核文件夹、用户添加、密码更改等。Falco 包括一个用户空间程序作为 CLI 工具,用于指定警报并获取解析的系统调用输出,以及一个基于 libscap 和 libsinsp 库构建的 falco 驱动程序。对于系统调用探针,falco 使用 eBPF 环形缓冲区。
Cilium
Cilium 中的可观测性是使用 eBPF 启用的。Hubble 是一个平台,其 eBPF 挂钩在集群的每个节点上运行。它有助于深入了解彼此通信的服务,以构建服务依赖关系图。它还有助于第 7 层监控以分析例如 HTTP 调用以及 Kafka 主题,第 4 层监控具有 TCP 重传率等等。
Tetragon
Tetragon 是 Cilium 中用于安全和可观测性的可扩展框架。tetragon 的底层支持者是 eBPF,数据使用环形缓冲区存储,但除了监控之外,还利用 eBPF 来强制执行跨越各种内核组件(例如虚拟文件系统 (VFS)、命名空间、系统调用)的策略。
Aquasecurity Tracee
Tracee 是一个事件跟踪工具,用于调试基于 eBPF 构建的行为模式。Tracee 在 tc、kprobes 等处有多个挂钩点,以监控和跟踪网络流量。在 tc 挂钩处,它使用环形缓冲区 (perf) 将数据包级事件提交到用户空间。
重新审视流指标代理的设计
虽然不同工具的动机和实现方式有所不同,但所有可观测性工具通用的核心组件是用于收集可观测性指标的数据结构。虽然不同的工具采用不同的数据结构来收集指标,但目前还没有进行任何性能测量来查看用于收集和存储可观测性指标的数据结构的影响。为了弥合这一差距,我们使用不同的数据结构实现了模板 eBPF 程序,以从主机流量中收集相同的流指标。我们使用 eBPF 中可用的以下数据结构(称为 Map)来收集和存储指标
- 环形缓冲区
- 哈希
- 每 CPU 哈希
- 数组
- 每 CPU 数组
环形缓冲区
环形缓冲区
是 eBPF 数据路径和用户空间之间的共享队列,其中 eBPF 数据路径是生产者,用户空间程序是消费者。它可用于将每个数据包的“明信片”发送到用户空间,以聚合流指标。虽然这种方法可能很简单并且提供准确的结果,但它无法扩展,因为它会按数据包发送明信片,这会使用户空间程序处于繁忙循环中。
哈希和每 CPU 哈希映射
(每 CPU)哈希映射可用于在 eBPF 数据路径中通过对流 ID(例如,5 元组 IP、端口、协议)进行哈希处理来聚合每流指标,并在流完成/不活动时将聚合信息逐出到用户空间。虽然这种方法通过仅在每个流而不是每个数据包发送一次明信片来克服了环形缓冲区的缺点,但它也有一些缺点。
首先,可能会有多个流被哈希到同一个条目中,从而导致流指标的聚合不准确。其次,哈希映射对于内核 eBPF 数据路径来说必然具有有限的内存,因此可能会耗尽。因此,用户空间程序必须实现逐出逻辑,以便在超时时不断逐出流。
基于数组的映射
(每 CPU)基于数组的映射也可以用于临时存储每个数据包的明信片,然后再逐出到用户空间,尽管这不是一个明显的选择。使用数组的优点在于,它会将每个数据包的信息存储在数组中,直到数组已满,然后在数组已满时才刷新到用户空间。这样,与使用每个数据包的环形缓冲区相比,它可以改善用户空间的繁忙循环。此外,它没有哈希映射的哈希冲突问题。但是,实现起来很复杂,因为它需要多个冗余数组来存储每个数据包的明信片,而主数组正在将其内容刷新到用户空间。
测量
到目前为止,我们已经研究了可用于使用多种数据结构实现流指标收集的选项。现在是时候研究使用上述每种数据结构的流指标明信片的参考实现所实现的性能了。为此,我们实现了收集流指标的代表性 eBPF 程序。我们使用的代码可在我们的 Git 仓库中找到。此外,我们通过使用基于 PcapPlusPlus 构建的自定义 UDP 数据包生成器发送流量来进行测量。
此图描述了实验设置
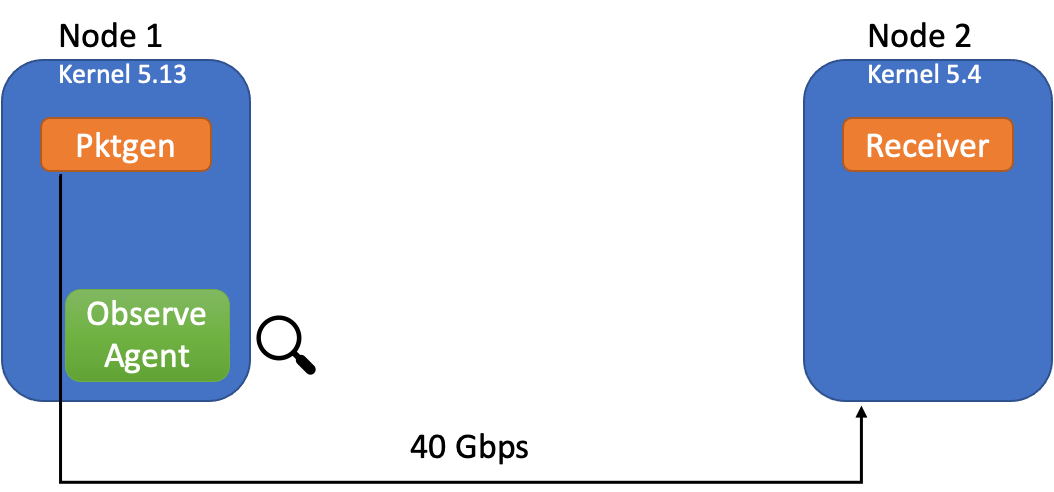
(Kannan/Naik/Lev-Ran,CC BY-SA 4.0)
观察代理是执行流指标收集的 eBPF 数据路径,挂钩在发送方的 tc 挂钩点。我们使用通过 40G 链路连接的两台裸机服务器。数据包生成使用 40 个独立的内核完成。为了使这些测量具有视角,可以使用基于 libpcap 的 Tcpdump 来收集类似的流信息。
单流
我们最初使用单流 UDP 帧运行测试。单流测试可以向我们展示观察代理可以容忍的单流流量突发量。如下图所示,没有任何观察代理的本机性能约为 4.7 Mpps(每秒百万个数据包),而运行 tcpdump 时,吞吐量降至约 2 Mpps。使用 eBPF,我们观察到性能在 1.6 Mpps 到 4.7 Mpps 之间变化,具体取决于用于存储流指标的数据结构。使用诸如 HashMap 之类的共享数据结构,我们观察到单流性能下降最为显着,因为无论数据包来自哪个 CPU,每个数据包都会写入映射中的同一条目。
对于单流突发,环形缓冲区的性能略好于单个 HashMap。使用每 CPU 哈希映射,我们观察到吞吐量性能显着提高,因为来自多个 CPU 的数据包不再争用同一个映射条目。但是,性能仍然是没有观察代理的本机性能的一半。(请注意,此性能不处理哈希冲突和逐出。)
使用(每 CPU)数组,我们看到单流的吞吐量显着增加。我们可以将此归因于事实上数据包之间实际上没有争用,因为每个数据包都以递增方式占用数组中的不同条目。但是,我们实现中的主要缺点是我们不处理数组在满时的刷新,而它以循环方式执行写入。因此,它存储在任何时间点观察到的最后几个数据包记录。尽管如此,它为我们提供了可以通过在 eBPF 数据路径中适当应用数据结构来实现的性能增益范围。
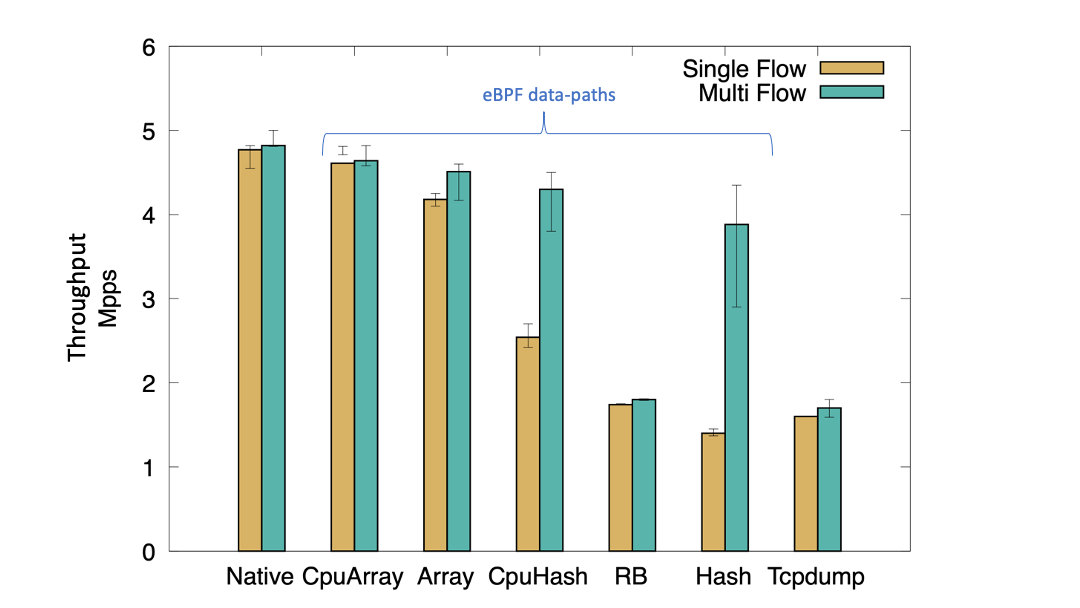
(Kannan/Naik/Lev-Ran,CC BY-SA 4.0)
多流
我们现在使用多个流测试 eBPF 观察代理的性能。我们通过工具化数据包生成器生成了 40 个不同的 UDP 流(每个内核 1 个流)。有趣的是,对于多个流,我们观察到每 CPU 哈希和哈希映射的性能与单流相比存在显着差异。这可能归因于单个哈希条目的争用减少。 但是,我们没有看到环形缓冲区的任何性能改进,因为无论流如何,争用通道,即环形缓冲区是固定的。数组在多流下的性能略好。
经验教训
从我们的研究中,我们得出了以下结论
- 基于环形缓冲区的每个数据包明信片不可扩展,并且会影响性能。
- 哈希映射限制了流的“突发性”,即每秒处理的数据包数量。每 CPU 哈希映射的性能略好。
- 为了处理流中的短突发数据包,使用数组映射来存储每个数据包的明信片将是一个不错的选择,因为数组可以存储少量数据包(10 个或 100 个数据包记录)。这将确保观察代理能够容忍短突发而不会降低性能。
在我们的研究中,我们分析了云中多个主机之间的数据包级和流级信息的监控。我们从可观测性的核心特征是以非侵入方式收集数据这一前提开始。基于这种观点,我们调查了现有工具,并测试了以从 eBPF 数据路径中观察到的数据包中收集的流指标的形式收集可观测性数据的不同方法。我们研究了流的性能如何受到用于收集流指标的数据结构的影响。
理想情况下,为了最大限度地减少由于可观测性代理的开销而导致的主机流量性能下降,我们的分析指向混合使用每 CPU 数组和每 CPU 哈希数据结构。这两种数据结构可以一起使用,以处理流中的短突发,使用数组和使用每 CPU 哈希映射进行聚合。我们目前正在开发可观测性代理 (https://github.com/netobserv/netobserv-ebpf-agent),并计划发布一篇未来的文章,其中包含设计细节以及与现有工具相比的性能分析。
[ 下载电子书: 管理您的 Linux 环境以获得成功 ]







5 条评论