

开源软件中最古老的笑话是“代码是自文档化的”这句话。经验表明,阅读源代码就像听天气预报:明智的人仍然会走到户外看看天空。接下来是一些关于如何通过利用熟悉的调试工具的知识来检查和观察 Linux 系统启动的技巧。分析运行良好的系统的启动过程,可以帮助用户和开发者为应对不可避免的故障做好准备。
在某些方面,启动过程出奇地简单。内核在单核上以单线程和同步方式启动,对于可怜的人类大脑来说,似乎几乎可以理解。但是内核本身是如何启动的呢?initrd (initial ramdisk) 和引导加载程序执行什么功能?等等,为什么以太网端口上的 LED 总是亮着?
请继续阅读以获得这些问题和其他问题的答案;所描述的演示和练习的代码也可在 GitHub 上找到。
启动的开始:OFF 状态
网络唤醒
OFF 状态意味着系统没有电源,对吗?表面上的简单具有欺骗性。例如,以太网 LED 亮起是因为您的系统上启用了网络唤醒 (WOL)。通过键入以下命令检查是否是这种情况
$# sudo ethtool <interface name>其中 <interface name> 可能是,例如,eth0。(ethtool 在同名的 Linux 软件包中可以找到。)如果输出中的“Wake-on”显示 g,则远程主机可以通过发送 MagicPacket 来启动系统。如果您无意远程唤醒您的系统,也不希望其他人这样做,请在系统 BIOS 菜单中或通过以下方式关闭 WOL
$# sudo ethtool -s <interface name> wol d响应 MagicPacket 的处理器可能是网络接口的一部分,也可能是 基板管理控制器 (BMC)。
英特尔管理引擎、平台控制器中心和 Minix
BMC 不是系统名义上关闭时可能正在侦听的唯一微控制器 (MCU)。x86_64 系统还包括英特尔管理引擎 (IME) 软件套件,用于系统的远程管理。从服务器到笔记本电脑的各种设备都包含这项技术,它实现了诸如 KVM 远程控制和英特尔功能许可服务等功能。根据 英特尔自己的检测工具,IME 存在未修补的漏洞。坏消息是,很难禁用 IME。Trammell Hudson 创建了一个 me_cleaner 项目,该项目擦除了一些更令人震惊的 IME 组件,例如嵌入式 Web 服务器,但也可能使运行它的系统变砖。
IME 固件和随后在启动时出现的系统管理模式 (SMM) 软件基于 Minix 操作系统,并在单独的平台控制器中心处理器而不是主系统 CPU 上运行。然后 SMM 在主处理器上启动通用可扩展固件接口 (UEFI) 软件,关于 UEFI 的许多内容已经被撰写。谷歌的 Coreboot 团队启动了一个令人叹为观止的雄心勃勃的非可扩展精简固件 (NERF) 项目,该项目旨在不仅取代 UEFI,还取代早期的 Linux 用户空间组件,例如 systemd。在我们等待这些新努力的结果时,Linux 用户现在可以从 Purism、System76 或戴尔购买禁用 IME 的笔记本电脑,此外,我们可以期待配备 ARM 64 位处理器的笔记本电脑。
引导加载程序
除了启动有缺陷的间谍软件外,早期启动固件还有什么功能?引导加载程序的工作是为新加电的处理器提供运行通用操作系统(如 Linux)所需的资源。在加电时,不仅没有虚拟内存,而且在 DRAM 控制器启动之前也没有 DRAM。然后,引导加载程序打开电源并扫描总线和接口,以便找到内核映像和根文件系统。流行的引导加载程序(如 U-Boot 和 GRUB)支持熟悉的接口,如 USB、PCI 和 NFS,以及更多特定于嵌入式的设备,如 NOR 和 NAND 闪存。引导加载程序还与硬件安全设备(如 可信平台模块 (TPM))交互,以建立从最早启动开始的信任链。
opensource.com
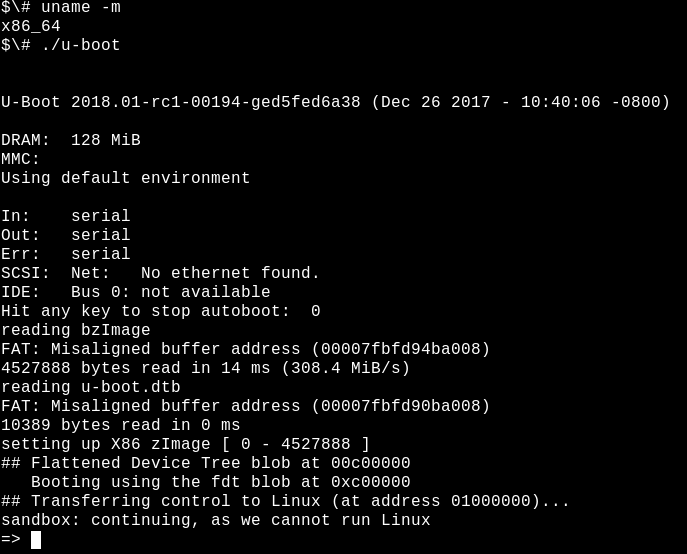
开源、广泛使用的 U-Boot 引导加载程序在从 Raspberry Pi 到 Nintendo 设备到汽车板到 Chromebook 的各种系统上都受支持。没有 syslog,当事情出错时,通常甚至没有任何控制台输出。为了方便调试,U-Boot 团队提供了一个沙箱,可以在构建主机上甚至在夜间持续集成系统中测试补丁。在安装了 Git 和 GNU 编译器套件 (GCC) 等常用开发工具的系统上,玩转 U-Boot 的沙箱相对简单
$# git clone git://git.denx.de/u-boot; cd u-boot
$# make ARCH=sandbox defconfig
$# make; ./u-boot
=> printenv
=> help就是这样:您正在 x86_64 上运行 U-Boot,并且可以测试棘手的功能,例如 模拟存储设备 重新分区、基于 TPM 的密钥操作以及 USB 设备的热插拔。U-Boot 沙箱甚至可以在 GDB 调试器下单步执行。使用沙箱进行开发比通过将引导加载程序重新刷新到板上来进行测试快 10 倍,并且可以通过 Ctrl+C 恢复“变砖”的沙箱。
启动内核
配置启动内核
完成其任务后,引导加载程序将执行跳转到它已加载到主内存中的内核代码并开始执行,并传递用户指定的任何命令行选项。内核是什么样的程序?file /boot/vmlinuz 表明它是一个 bzImage,意味着一个大的压缩映像。Linux 源代码树包含一个 extract-vmlinux 工具,可用于解压缩该文件
$# scripts/extract-vmlinux /boot/vmlinuz-$(uname -r) > vmlinux
$# file vmlinux
vmlinux: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), statically
linked, stripped内核是一个 可执行和链接格式 (ELF) 二进制文件,就像 Linux 用户空间程序一样。这意味着我们可以使用 binutils 包中的命令(如 readelf)来检查它。比较例如以下命令的输出
$# readelf -S /bin/date
$# readelf -S vmlinux二进制文件中的节列表在很大程度上是相同的。
因此,内核必须像其他 Linux ELF 二进制文件一样启动……但是用户空间程序实际上是如何启动的呢?在 main() 函数中,对吗?不完全是。
在 main() 函数可以运行之前,程序需要一个执行上下文,其中包括堆和栈内存以及 stdio、stdout 和 stderr 的文件描述符。用户空间程序从标准库(在大多数 Linux 系统上是 glibc)获取这些资源。考虑以下情况
$# file /bin/date
/bin/date: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically
linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 2.6.32,
BuildID[sha1]=14e8563676febeb06d701dbee35d225c5a8e565a,
strippedELF 二进制文件有一个解释器,就像 Bash 和 Python 脚本一样,但解释器不需要像脚本中那样用 #! 指定,因为 ELF 是 Linux 的本机格式。ELF 解释器 通过调用 _start() 为二进制文件提供所需资源,_start() 是 glibc 源代码包中可用的函数,可以通过 GDB 进行检查。内核显然没有解释器,必须自行配置,但如何配置呢?
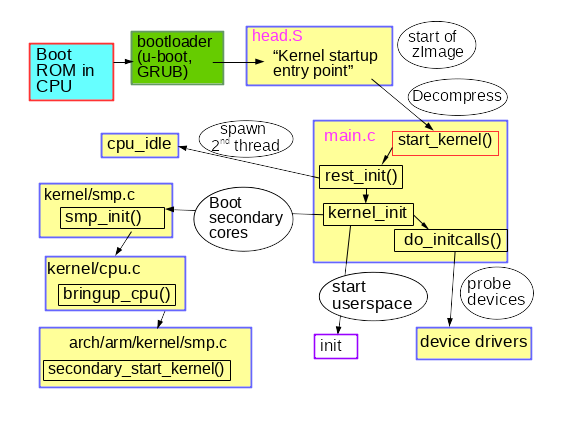
使用 GDB 检查内核的启动过程可以给出答案。首先安装内核的调试包,其中包含未剥离版本的 vmlinux,例如 apt-get install linux-image-amd64-dbg,或者从源代码编译并安装您自己的内核,例如,按照优秀的 Debian 内核手册 中的说明进行操作。gdb vmlinux 后跟 info files 显示 ELF 节 init.text。使用 l *(address) 列出 init.text 中程序执行的开始位置,其中 address 是 init.text 的十六进制起始地址。GDB 将指示 x86_64 内核在内核文件 arch/x86/kernel/head_64.S 中启动,我们在其中找到汇编函数 start_cpu0() 和在调用 x86_64 start_kernel() 函数之前显式创建堆栈并解压缩 zImage 的代码。ARM 32 位内核具有类似的 arch/arm/kernel/head.S。start_kernel() 不是特定于架构的,因此该函数位于内核的 init/main.c 中。start_kernel() 可以说是 Linux 真正的 main() 函数。
从 start_kernel() 到 PID 1
内核的硬件清单:设备树和 ACPI 表
在启动时,内核需要的硬件信息不仅仅是它已编译的处理器类型。代码中的指令通过单独存储的配置数据进行扩充。存储此数据有两种主要方法:设备树 和 ACPI 表。内核通过读取这些文件来了解每次启动时必须运行的硬件。
对于嵌入式设备,设备树是已安装硬件的清单。设备树只是一个文件,它与内核源代码同时编译,通常与 vmlinux 一起位于 /boot 中。要查看 ARM 设备上的二进制设备树中的内容,只需在文件名与 /boot/*.dtb 匹配的文件上使用 binutils 包中的 strings 命令,因为 dtb 指的是设备树二进制文件。显然,只需编辑组成设备树的类似 JSON 的文件并重新运行内核源代码提供的特殊 dtc 编译器,即可修改设备树。虽然设备树是一个静态文件,其文件路径通常由引导加载程序在命令行上传递给内核,但在最近几年中添加了一个 设备树覆盖 功能,其中内核可以动态加载其他片段以响应启动后的热插拔事件。
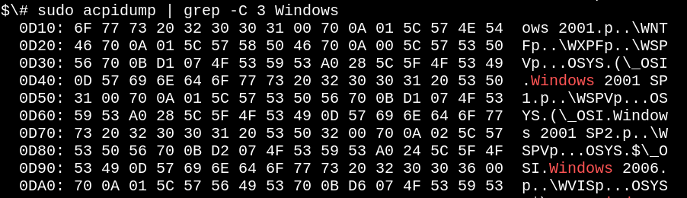
x86 系列和许多企业级 ARM64 设备使用替代的高级配置和电源接口 (ACPI) 机制。与设备树相比,ACPI 信息存储在 /sys/firmware/acpi/tables 虚拟文件系统中,该文件系统由内核在启动时通过访问板载 ROM 创建。读取 ACPI 表的简单方法是使用 acpica-tools 包中的 acpidump 命令。这是一个例子
opensource.com
是的,如果需要安装 Windows 2001,您的 Linux 系统已准备就绪。ACPI 既有方法又有数据,这与设备树不同,设备树更像是一种硬件描述语言。ACPI 方法在启动后继续处于活动状态。例如,启动命令 acpi_listen(来自软件包 apcid)并打开和关闭笔记本电脑盖将显示 ACPI 功能一直在运行。虽然可以临时和动态地覆盖 ACPI 表,但永久更改它们涉及在启动时与 BIOS 菜单交互或重新刷新 ROM。如果您要付出这么多麻烦,也许您应该只安装 coreboot,即开源固件替代品。
从 start_kernel() 到用户空间
init/main.c 中的代码非常易读,而且有趣的是,仍然带有 Linus Torvalds 从 1991-1992 年的原始版权。在新启动的系统上在 dmesg | head 中找到的行主要来自此源文件。第一个 CPU 在系统中注册,全局数据结构被初始化,并且调度程序、中断处理程序 (IRQ)、计时器和控制台依次严格地联机。在 timekeeping_init() 函数运行之前,所有时间戳均为零。内核初始化的这部分是同步的,这意味着执行精确地在一个线程中发生,并且在上一个函数完成并返回之前不会执行任何函数。因此,只要它们具有相同的设备树或 ACPI 表,即使在两个系统之间,dmesg 输出也将完全可重现。Linux 的行为类似于在 MCU 上运行的 RTOS(实时操作系统),例如 QNX 或 VxWorks。这种情况一直持续到 rest_init() 函数,该函数由 start_kernel() 在其终止时调用。
opensource.com
以相当谦虚的名字命名的 rest_init() 产生一个新的线程,该线程运行 kernel_init(),后者调用 do_initcalls()。用户可以通过将 initcall_debug 附加到内核命令行来监视 initcalls 的运行,从而在每次 initcall 函数运行时生成 dmesg 条目。initcalls 经历七个连续级别:early、core、postcore、arch、subsys、fs、device 和 late。initcalls 最用户可见的部分是所有处理器外围设备的探测和设置:总线、网络、存储、显示器等,以及它们的内核模块的加载。rest_init() 还在启动处理器上产生第二个线程,该线程首先运行 cpu_idle(),同时等待调度程序为其分配工作。
kernel_init() 还 设置了对称多处理 (SMP)。对于更新的内核,通过在 dmesg 输出中查找“Bringing up secondary CPUs...”来找到这一点。SMP 通过“热插拔”CPU 来进行,这意味着它使用状态机管理它们的生命周期,该状态机在概念上类似于热插拔 USB 闪存盘等设备的生命周期。内核的电源管理系统经常使各个内核脱机,然后在需要时唤醒它们,以便在不繁忙的机器上反复调用相同的 CPU 热插拔代码。使用名为 offcputime.py 的 BCC 工具 观察电源管理系统对 CPU 热插拔的调用。
请注意,当 smp_init() 运行时,init/main.c 中的代码几乎已完成执行:启动处理器已完成其他内核不需要重复的大部分一次性初始化。尽管如此,必须为每个内核生成每个 CPU 线程,以管理每个内核上的中断 (IRQ)、工作队列、计时器和电源事件。例如,通过 ps -o psr 命令查看为软中断和工作队列提供服务的每个 CPU 线程的运行情况。
$\# ps -o pid,psr,comm $(pgrep ksoftirqd)
PID PSR COMMAND
7 0 ksoftirqd/0
16 1 ksoftirqd/1
22 2 ksoftirqd/2
28 3 ksoftirqd/3
$\# ps -o pid,psr,comm $(pgrep kworker)
PID PSR COMMAND
4 0 kworker/0:0H
18 1 kworker/1:0H
24 2 kworker/2:0H
30 3 kworker/3:0H
[ . . . ]其中 PSR 字段代表“处理器”。每个内核还必须托管自己的计时器和 cpuhp 热插拔处理程序。
最终,用户空间是如何启动的呢?在其末尾附近,kernel_init() 查找可以代表其执行 init 进程的 initrd。如果找不到,内核将直接执行 init 本身。那么,为什么有人会想要 initrd 呢?
早期用户空间:谁订购了 initrd?
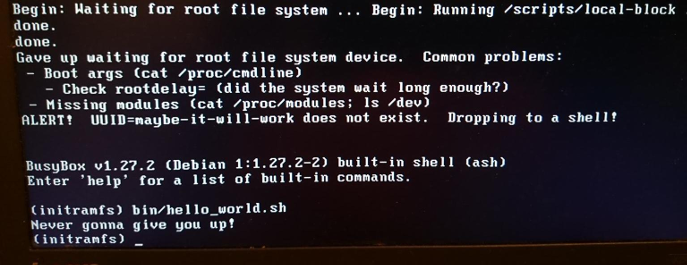
除了设备树之外,在启动时可选地提供给内核的另一个文件路径是 initrd 的路径。initrd 通常与 x86 上的 bzImage 文件 vmlinuz 或 ARM 的类似 uImage 和设备树一起位于 /boot 中。使用作为 initramfs-tools-core 包一部分的 lsinitramfs 工具列出 initrd 的内容。发行版 initrd 方案包含最小的 /bin、/sbin 和 /etc 目录以及内核模块,以及 /scripts 中的一些文件。所有这些都应该看起来非常熟悉,因为 initrd 在很大程度上只是一个最小的 Linux 根文件系统。表面上的相似性有点具有欺骗性,因为 ramdisk 内 /bin 和 /sbin 中的几乎所有可执行文件都是指向 BusyBox 二进制文件 的符号链接,从而导致 /bin 和 /sbin 目录比 glibc 的小 10 倍。
如果 initrd 所做的只是加载一些模块,然后在常规根文件系统上启动 init,那为什么还要费心创建 initrd 呢?考虑一个加密的根文件系统。解密可能依赖于加载存储在根文件系统上的 /lib/modules 中的内核模块……并且,不出所料,也存储在 initrd 中。加密模块可以静态编译到内核中,而不是从文件中加载,但有各种原因不想这样做。例如,使用模块静态编译内核可能会使其太大而无法放入可用存储空间,或者静态编译可能会违反软件许可条款。不出所料,存储、网络和人机输入设备 (HID) 驱动程序也可能存在于 initrd 中——基本上是挂载根文件系统所需的任何不属于内核本身的代码。initrd 也是用户可以存放自己的 自定义 ACPI 表代码的地方。
opensource.com
initrd 也非常适合测试文件系统和数据存储设备本身。将这些测试工具存放在 initrd 中,并从内存而不是从被测对象运行测试。
最后,当 init 运行时,系统就启动了!由于辅助处理器现在正在运行,因此机器已成为我们所了解和喜爱的异步、可抢占、不可预测、高性能的生物。实际上,ps -o pid,psr,comm -p 1 很可能表明用户空间的 init 进程不再在启动处理器上运行。
总结
考虑到即使在简单的嵌入式设备上也有许多不同的软件参与,Linux 启动过程听起来令人望而生畏。从另一个角度来看,启动过程相当简单,因为在启动过程中不存在抢占、RCU 和竞争条件等特性造成的令人眼花缭乱的复杂性。仅关注内核和 PID 1 忽略了引导加载程序和辅助处理器可能在准备平台以供内核运行方面所做的大量工作。虽然内核在 Linux 程序中肯定是独一无二的,但通过对其应用一些用于检查其他 ELF 二进制文件的相同工具,可以了解其结构的一些见解。在启动过程运行良好时对其进行研究,可以帮助系统维护人员应对故障。
要了解更多信息,请参加 Alison Chaiken 在 linux.conf.au 上的演讲 Linux: The first second,该会议将于 1 月 22 日至 26 日在悉尼举行。
感谢 Akkana Peck 最初提出这个话题并进行了许多更正。





8 条评论