

当我们最初开源 Spark 时,我们的目标是为通用编程语言(Java、Python、Scala)中的分布式数据处理提供一个简单的 API。 Spark 通过分布式数据集合(RDD)上的函数式转换实现了分布式数据处理。这是一个非常强大的 API——过去需要数千行代码表达的任务可以减少到几十行。
随着 Spark 的不断发展,我们希望让更多大数据工程师之外的受众能够利用分布式处理的强大功能。 新的 DataFrame API 就是为了这个目标而创建的。 这个 API 的灵感来自 R 和 Python (Pandas) 中的数据帧,但从头开始设计,以支持现代大数据和数据科学应用。 作为现有 RDD API 的扩展,DataFrames 具有
- 能够从单台笔记本电脑上的千字节数据扩展到大型集群上的 PB 级数据
- 支持各种数据格式和存储系统
- 通过 Spark SQL Catalyst 优化器 实现最先进的优化和代码生成
- 通过 Spark 与所有大数据工具和基础设施无缝集成
- 适用于 Python、Java、Scala 和 R 的 API(通过 SparkR 开发中)
对于熟悉其他编程语言中的数据帧的新用户,此 API 应该让他们感到宾至如归。 对于现有的 Spark 用户,这个扩展的 API 将使 Spark 更容易编程,同时通过智能优化和代码生成提高性能。
什么是 DataFrames?
在 Spark 中,DataFrame 是一个分布式的数据集合,组织成命名列。 在概念上,它等同于关系数据库中的表或 R/Python 中的数据帧,但在底层具有更丰富的优化。 DataFrames 可以从各种来源构建,例如:结构化数据文件、Hive 中的表、外部数据库或现有的 RDD。
以下示例显示了如何在 Python 中构造 DataFrames。 Scala 和 Java 中也提供了类似的 API。
# 从 Hive 中的 users 表构造 DataFrame。 users = context.table( users )
# 从 S3 中的 JSON 文件 logs = context.load( s3n://path/to/data.json , json )
如何使用 DataFrames?
构建完成后,DataFrames 提供了一种特定于领域的语言用于分布式数据操作。 这是一个使用 DataFrames 操作大量用户的人口统计数据的示例
# 创建一个仅包含“年轻用户”的新 DataFrame
young = users.filter(users.age < 21)
# 或者,使用类似 Pandas 的语法
young = users[users.age < 21]
# 将每个人的年龄增加 1
young.select(young.name, young.age + 1)
# 按性别计算年轻用户的数量
young.groupBy( gender ).count()
# 将年轻用户与另一个名为 logs 的 DataFrame 连接起来
young.join(logs, logs.userId == users.userId, left_outer )
在使用 DataFrames 时,您还可以使用 Spark SQL 合并 SQL。 此示例计算 young DataFrame 中的用户数。
young.registerTempTable( young )
context.sql( SELECT count(*) FROM young )
在 Python 中,您还可以在 Pandas DataFrame 和 Spark DataFrame 之间自由转换
# 将 Spark DataFrame 转换为 Pandas
pandas_df = young.toPandas()
# 从 Pandas 创建一个 Spark DataFrame spark_df = context.createDataFrame(pandas_df)
与 RDD 类似,DataFrames 是延迟评估的。 也就是说,只有在需要执行操作(例如,显示结果,保存输出)时才会进行计算。 这允许通过应用诸如谓词下推和字节码生成之类的技术来优化它们的执行,如后面的“底层原理:智能优化和代码生成”部分中所述。 所有 DataFrame 操作也会自动并行化并在集群上分布。
支持的数据格式和来源
现代应用程序通常需要从各种来源收集和分析数据。 DataFrame 开箱即用,支持从最流行的格式读取数据,包括 JSON 文件、Parquet 文件和 Hive 表。 它可以从本地文件系统、分布式文件系统 (HDFS)、云存储 (S3) 以及通过 JDBC 的外部关系数据库系统读取数据。 此外,通过 Spark SQL 的 外部数据源 API,DataFrames 可以扩展到支持任何第三方数据格式或来源。 现有的第三方扩展已经包括 Avro、CSV、ElasticSearch 和 Cassandra。
DataFrames 对数据源的支持使应用程序可以轻松地组合来自不同来源的数据(在数据库系统中称为联邦查询处理)。 例如,以下代码片段将存储在 S3 中的站点的文本流量日志与 PostgreSQL 数据库连接起来,以计算每个用户访问该站点的次数。
users = context.jdbc( jdbc:postgresql:production , users )
logs = context.load( /path/to/traffic.log )
logs.join(users, logs.userId == users.userId, left_outer ) \
.groupBy( userId ).agg({ * : count })
应用:高级分析和机器学习
数据科学家正在采用越来越复杂的技术,这些技术超越了连接和聚合。 为了支持这一点,DataFrames 可以直接在 MLlib 的 机器学习管道 API 中使用。 此外,程序可以在 DataFrames 上运行任意复杂的用户函数。
可以使用 MLlib 中的新管道 API 指定最常见的高级分析任务。 例如,以下代码创建一个简单的文本分类管道,该管道由一个分词器、一个哈希术语频率特征提取器和逻辑回归组成。
tokenizer = Tokenizer(inputCol= text , outputCol= words )
hashingTF = HashingTF(inputCol= words , outputCol= features )
lr = LogisticRegression(maxIter=10, regParam=0.01)
pipeline = Pipeline(stages=[tokenizer, hashingTF, lr])
设置好管道后,我们可以使用它直接在 DataFrame 上进行训练
df = context.load( /path/to/data )
model = pipeline.fit(df)
对于超出机器学习管道 API 提供的更复杂的任务,应用程序还可以在 DataFrame 上应用任意复杂的函数,也可以使用 Spark 现有的 RDD API 对其进行操作。 以下代码片段对 DataFrame 的 bio 列执行字数统计,这是大数据的“Hello World”。
df = context.load( /path/to/people.json )
# RDD 样式的方法(例如 map、flatMap)在 DataFrames 上可用
# 将 bio 文本拆分为多个单词。
words = df.select( bio ).flatMap(lambda row: row.bio.split( ))
# 创建一个新的 DataFrame 来计算单词数 words_df = words.map(lambda w: Row(word=w, cnt=1)).toDF()
word_counts = words_df.groupBy( word ).sum()
底层原理:智能优化和代码生成
与 R 和 Python 中急切评估的数据帧不同,Spark 中的 DataFrames 的执行由查询优化器自动优化。 在 DataFrame 上开始任何计算之前,Catalyst 优化器 会将用于构建 DataFrame 的操作编译成物理执行计划。 因为优化器了解操作的语义和数据的结构,所以它可以做出智能决策来加速计算。
从高层次上讲,有两种优化。 首先,Catalyst 应用逻辑优化,例如谓词下推。 优化器可以将过滤器谓词下推到数据源中,使物理执行能够跳过不相关的数据。 在 Parquet 文件的情况下,可以跳过整个块,并且可以通过字典编码将字符串的比较转换为更便宜的整数比较。 在关系数据库的情况下,谓词被下推到外部数据库中,以减少数据流量。
其次,Catalyst 将操作编译成物理执行计划,并为这些计划生成 JVM 字节码,这些字节码通常比手写代码更优化。 例如,它可以智能地选择广播连接和混洗连接之间,以减少网络流量。 它还可以执行更低级别的优化,例如消除昂贵的对象分配和减少虚拟函数调用。 因此,我们希望现有的 Spark 程序迁移到 DataFrames 时能够提高性能。
由于优化器为执行生成 JVM 字节码,因此 Python 用户将体验到与 Scala 和 Java 用户相同的高性能。
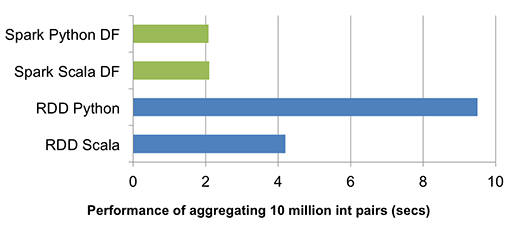
上图比较了在单台机器上对 1000 万个整数对运行分组聚合的运行时性能(源代码)。 由于 Scala 和 Python DataFrame 操作都被编译成 JVM 字节码以供执行,因此两种语言之间几乎没有区别,并且都比 vanilla Python RDD 变体快五倍,比 Scala RDD 变体快两倍。
DataFrames 的灵感来源于之前的一些分布式数据框架尝试,包括 Adatao 的 DDF 和 Ayasdi 的 BigDF。 然而,与这些项目的主要区别在于 DataFrames 通过 Catalyst 优化器,能够实现类似于 Spark SQL 查询的优化执行。 随着我们不断改进 Catalyst 优化器,引擎也会变得更加智能,从而使应用程序在每个新的 Spark 版本中都变得更快。
我们在 Databricks 的数据科学团队一直在内部数据管道上使用这个新的 DataFrame API。 它为我们的 Spark 程序带来了性能提升,同时使它们更加简洁易懂。 我们对此感到非常兴奋,并相信它将使大数据处理更易于广大用户使用。
此 API 是 Spark 1.3 的一部分。 您可以从我上个月的演示文稿中了解更多信息(幻灯片, 视频)。 请尝试一下。 我们期待您的反馈。





1 条评论