

用户有很多选项可以自定义和扩展 ShardingSphere 的高可用性 (HA) 解决方案。我们的团队已经完成了两个 HA 计划:一个基于 MGR 的 MySQL 高可用性解决方案,以及一些社区提交者贡献的 openGauss 数据库高可用性解决方案。 这两个解决方案的原理是相同的。
以下是如何以及为什么 ShardingSphere 可以使用 MySQL 作为示例来实现数据库高可用性
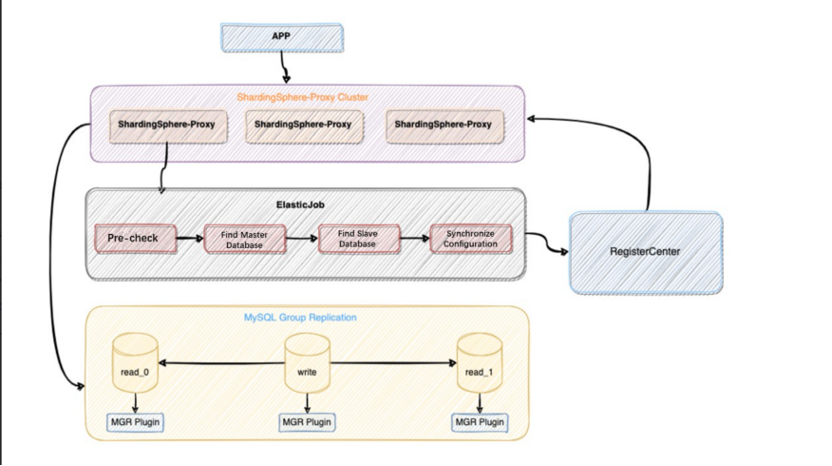
(Zhao Jinchao, CC BY-SA 4.0)
先决条件
ShardingSphere 通过执行以下 SQL 语句来检查底层 MySQL 集群环境是否准备就绪。 如果任何测试失败,ShardingSphere 将无法启动。
检查是否安装了 MGR
SELECT * FROM information_schema.PLUGINS WHERE PLUGIN_NAME='group_replication'查看 MGR 组成员数量。 底层 MGR 集群应至少包含三个节点
SELECT count(*) FROM performance_schema.replication_group_members检查 MGR 集群的组名是否与配置中的组名一致。 组名是 MGR 组的标记,MGR 集群的每个组只有一个组名
SELECT * FROM performance_schema.global_variables WHERE VARIABLE_NAME='group_replication_group_name' 检查当前 MGR 是否设置为单主模式。 目前,ShardingSphere 不支持双写或多写场景。 它仅支持单写模式
SELECT * FROM performance_schema.global_variables WHERE VARIABLE_NAME='group_replication_single_primary_mode'查询 MGR 组集群中的所有节点主机、端口和状态,以检查配置的数据源是否正确
SELECT MEMBER_HOST, MEMBER_PORT, MEMBER_STATE FROM performance_schema.replication_group_members动态主数据库发现
ShardingSphere 根据 MySQL 提供的查询主数据库 SQL 命令查找主数据库 URL
private String findPrimaryDataSourceURL(final Map<String, DataSource> dataSourceMap) {
String result = "";
String sql = "SELECT MEMBER_HOST, MEMBER_PORT FROM performance_schema.replication_group_members WHERE MEMBER_ID = "
+ "(SELECT VARIABLE_VALUE FROM performance_schema.global_status WHERE VARIABLE_NAME = 'group_replication_primary_member')";
for (DataSource each : dataSourceMap.values()) {
try (Connection connection = each.getConnection();
Statement statement = connection.createStatement();
ResultSet resultSet = statement.executeQuery(sql)) {
if (resultSet.next()) {
return String.format("%s:%s", resultSet.getString("MEMBER_HOST"), resultSet.getString("MEMBER_PORT"));
}
} catch (final SQLException ex) {
log.error("An exception occurred while find primary data source url", ex);
}
}
return result;
}将上述找到的主数据库 URL 与配置的 dataSources URL 逐一进行比较。 匹配的数据源是主数据库。 它将被更新到当前的 ShardingSphere 内存,并永久保存到注册中心,并通过该注册中心分发到集群中的其他计算节点。
(Zhao Jinchao, CC BY-SA 4.0)
动态备用数据库发现
ShardingSphere 中有两种类型的备用数据库状态:启用和禁用。 备用数据库状态将同步到 ShardingSphere 内存,以确保可以正确路由读取流量。
获取 MGR 组中的所有节点
SELECT MEMBER_HOST, MEMBER_PORT, MEMBER_STATE FROM performance_schema.replication_group_members禁用备用数据库
private void determineDisabledDataSource(final String schemaName, final Map<String, DataSource> activeDataSourceMap,
final List<String> memberDataSourceURLs, final Map<String, String> dataSourceURLs) {
for (Entry<String, DataSource> entry : activeDataSourceMap.entrySet()) {
boolean disable = true;
String url = null;
try (Connection connection = entry.getValue().getConnection()) {
url = connection.getMetaData().getURL();
for (String each : memberDataSourceURLs) {
if (null != url && url.contains(each)) {
disable = false;
break;
}
}
} catch (final SQLException ex) {
log.error("An exception occurred while find data source urls", ex);
}
if (disable) {
ShardingSphereEventBus.getInstance().post(new DataSourceDisabledEvent(schemaName, entry.getKey(), true));
} else if (!url.isEmpty()) {
dataSourceURLs.put(entry.getKey(), url);
}
}
}是否禁用备用数据库取决于配置的数据源和 MGR 组中的所有节点。
ShardingSphere 可以逐一检查配置的数据源是否可以正确获取 Connection,并验证数据源 URL 是否包含 MGR 组的节点。
如果无法获取 Connection 或验证失败,ShardingSphere 将通过事件触发器禁用数据源,并将其同步到注册中心。
启用备用数据库
private void determineEnabledDataSource(final Map<String, DataSource> dataSourceMap, final String schemaName,
final List<String> memberDataSourceURLs, final Map<String, String> dataSourceURLs) {
for (String each : memberDataSourceURLs) {
boolean enable = true;
for (Entry<String, String> entry : dataSourceURLs.entrySet()) {
if (entry.getValue().contains(each)) {
enable = false;
break;
}
}
if (!enable) {
continue;
}
for (Entry<String, DataSource> entry : dataSourceMap.entrySet()) {
String url;
try (Connection connection = entry.getValue().getConnection()) {
url = connection.getMetaData().getURL();
if (null != url && url.contains(each)) {
ShardingSphereEventBus.getInstance().post(new DataSourceDisabledEvent(schemaName, entry.getKey(), false));
break;
}
} catch (final SQLException ex) {
log.error("An exception occurred while find enable data source urls", ex);
}
}
}
}崩溃的备用数据库恢复并添加到 MGR 组后,将检查配置以查看是否使用了恢复的数据源。 如果是,事件触发器将告诉 ShardingSphere 需要启用该数据源。
心跳机制
HA 模块引入了心跳机制,以确保主备状态实时同步。
通过集成 ShardingSphere 子项目 ElasticJob,当 HA 模块初始化时,上述流程由 ElasticJob 调度框架以 Job 的形式执行,从而实现功能开发和作业调度的分离。
即使开发人员需要扩展 HA 功能,他们也不需要关心如何开发和操作作业
private void initHeartBeatJobs(final String schemaName, final Map<String, DataSource> dataSourceMap) {
Optional<ModeScheduleContext> modeScheduleContext = ModeScheduleContextFactory.getInstance().get();
if (modeScheduleContext.isPresent()) {
for (Entry<String, DatabaseDiscoveryDataSourceRule> entry : dataSourceRules.entrySet()) {
Map<String, DataSource> dataSources = dataSourceMap.entrySet().stream().filter(dataSource -> !entry.getValue().getDisabledDataSourceNames().contains(dataSource.getKey()))
.collect(Collectors.toMap(Entry::getKey, Entry::getValue));
CronJob job = new CronJob(entry.getValue().getDatabaseDiscoveryType().getType() + "-" + entry.getValue().getGroupName(),
each -> new HeartbeatJob(schemaName, dataSources, entry.getValue().getGroupName(), entry.getValue().getDatabaseDiscoveryType(), entry.getValue().getDisabledDataSourceNames())
.execute(null), entry.getValue().getHeartbeatProps().getProperty("keep-alive-cron"));
modeScheduleContext.get().startCronJob(job);
}
}
}总结
到目前为止,Apache ShardingSphere 的 HA 功能已被证明适用于 MySQL 和 openGauss HA 解决方案。 未来,它将集成更多 MySQL HA 产品并支持更多数据库 HA 解决方案。
与往常一样,如果您有兴趣,非常欢迎您加入我们并为 Apache ShardingSphere 项目做出贡献。
Apache ShardingSphere 开源项目链接




评论已关闭。