

在浏览 SQL 以准备面试时,我经常遇到这个问题:通过连接包含员工信息的表和包含部门信息的另一个表,找到薪水最高或(第二高)的员工。这引出了一个更深层次的问题:如何找到部门范围内薪水第 n 高的员工?
现在我想提出一个更复杂的情况:当某个部门没有员工获得第 n 高薪水时会发生什么?例如,一个只有两名员工的部门不会有员工获得第三高薪水。
这是我对这个问题的解决方法
创建部门和员工表
我创建了一个表,其中包括诸如 dept_id 和 dept_name 等字段。
CREATE TABLE department (
dept_id int,
dept_name varchar(60)
);现在我将各种部门插入到新表中。
INSERT INTO department (dept_id,dept_name)
VALUES (780,'HR');
INSERT INTO department (dept_id,dept_name)
VALUES (781,'Marketing');
INSERT INTO department (dept_id,dept_name)
VALUES (782,'Sales');
INSERT INTO department (dept_id,dept_name)
VALUES (783,'Web Dev');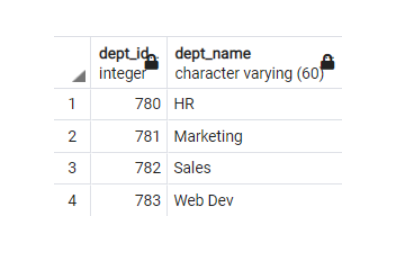
图 1. 部门表 (Mohammed Kamil Khan, CC BY-SA 4.0)
接下来,我创建另一个表,其中包含字段 first_name、last_name、dept_id 和 salary。
CREATE TABLE employee (
first_name varchar(100),
last_name varchar(100),
dept_id int,
salary int
);然后我将值插入到表中
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Sam','Burton',781,80000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Peter','Mellark',780,90000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Happy','Hogan',782,110000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Steve','Palmer',782,120000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Christopher','Walker',783,140000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Richard','Freeman',781,85000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Alex','Wilson',782,115000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Harry','Simmons',781,90000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Thomas','Henderson',780,95000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Ronald','Thompson',783,130000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('James','Martin',783,135000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Laurent','Fisher',780,100000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Tom','Brooks',780,85000);
INSERT INTO employee (first_name,last_name,dept_id,salary)
VALUES ('Tom','Bennington',783,140000);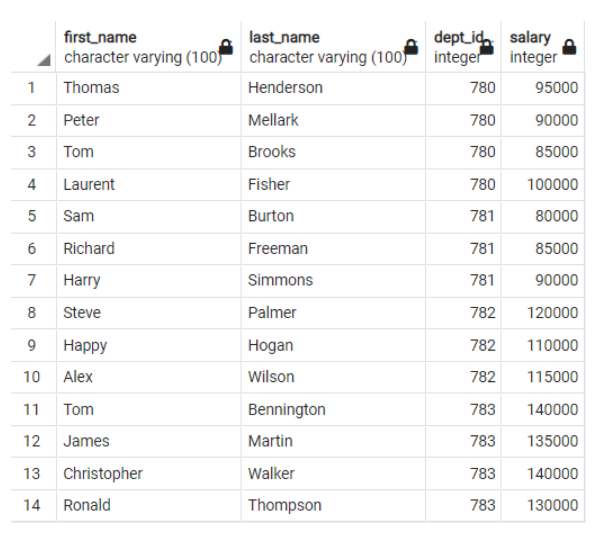
图 2. 按部门 ID 排序的员工表 (Mohammed Kamil Khan, CC BY-SA 4.0)
我可以使用此表推断每个部门的员工人数(部门 ID:员工人数)
- 780:4
- 781:3
- 782:3
- 783:4
如果我想查看来自不同部门的薪水第二高的员工,以及他们部门的名称(使用 DENSE_RANK),表格将如下所示
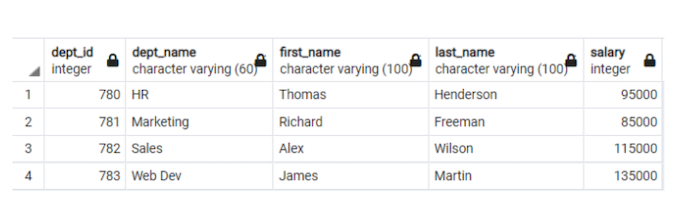
图 3. 每个部门薪水第二高的员工 (Mohammed Kamil Khan, CC BY-SA 4.0)
如果我应用相同的查询来查找薪水第四高的员工,则输出将只有部门 780 (HR) 的 Tom Brooks,薪水为 85,000 美元。

图 4. 薪水第四高的员工 (Mohammed Kamil Khan, CC BY-SA 4.0)
尽管部门 783 (Web Dev) 有四名员工,但其中两名(James Martin 和 Ronald Thompson)将被归类为该部门薪水第三高的员工,因为收入最高的前两名员工薪水相同。
查找第 n 高值
现在,回到主要问题:如果我想显示 dept_ID 和 dept_name,对于没有获得第 n 高薪水的员工的部门,员工相关字段显示为空值,该怎么办?

图 5. 列出所有部门,无论它们是否有获得第 n 高薪水的员工 (Mohammed Kamil Khan, CC BY-SA 4.0)
图 5 中显示的表格是我旨在获得的,当特定部门没有获得第 n 高薪水的员工时:市场营销部、销售部和 Web 开发部都列出来了,但姓名和薪水字段包含空值。
最终帮助获得图 5 中表格的查询如下
SELECT * FROM (WITH null1 AS (select A.dept_id, A.dept_name, A.first_name, A.last_name, A.salary
from (SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4)A),
full1 AS (SELECT dept_id, dept_name FROM department WHERE dept_id NOT IN (SELECT dept_id FROM null1 WHERE dept_id IS NOT null)),
nulled AS(SELECT
CASE WHEN null1.dept_id IS NULL THEN full1.dept_id ELSE null1.dept_id END,
CASE WHEN null1.dept_name IS NULL THEN full1.dept_name ELSE null1.dept_name END,
first_name,last_name,salary
FROM null1 RIGHT JOIN full1 ON null1.dept_id=full1.dept_id)
SELECT * from null1
UNION
SELECT * FROM nulled
ORDER BY dept_id)
B;查询分解
我将分解查询,使其不那么令人望而生畏。
使用 DENSE_RANK() 显示员工和部门信息(不涉及因缺少第 n 高薪水成员而产生的空值)
SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4输出

图 6. 薪水第四高的人 (Mohammed Kamil Khan, CC BY-SA 4.0)
从图 6 的表格中排除 rank1 列,该列仅识别出一位薪水第四高的员工,即使另一个部门有四名员工。
select A.dept_id, A.dept_name, A.first_name, A.last_name, A.salary
from (SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4)A输出

图 7. 没有 rank 1 列的薪水第四高员工表 (Mohammed Kamil Khan, CC BY-SA 4.0)
指出部门表中没有获得第 n 高薪水的员工的部门
SELECT * FROM (WITH null1 AS (select A.dept_id, A.dept_name, A.first_name, A.last_name, A.salary
from (SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4)A),
full1 AS (SELECT dept_id, dept_name FROM department WHERE dept_id NOT IN (SELECT dept_id FROM null1 WHERE dept_id IS NOT null))
SELECT * FROM full1)B输出

图 8. 列出没有第四高薪水获得者的部门的 full1 表 (Mohammed Kamil Khan, CC BY-SA 4.0)
将上面代码最后一行中的 full1 替换为 null1
SELECT * FROM (WITH null1 AS (select A.dept_id, A.dept_name, A.first_name, A.last_name, A.salary
from (SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4)A),
full1 AS (SELECT dept_id, dept_name FROM department WHERE dept_id NOT IN (SELECT dept_id FROM null1 WHERE dept_id IS NOT null))
SELECT * FROM null1)B
图 9. null1 表,列出所有部门,对于那些没有第四高薪水获得者的部门,其值为空值 (Mohammed Kamil Khan, CC BY-SA 4.0)
现在,我用图 8 中的相应值填充图 9 中 dept_id 和 dept_name 字段的空值。
SELECT * FROM (WITH null1 AS (select A.dept_id, A.dept_name, A.first_name, A.last_name, A.salary
from (SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4)A),
full1 AS (SELECT dept_id, dept_name FROM department WHERE dept_id NOT IN (SELECT dept_id FROM null1 WHERE dept_id IS NOT null)),
nulled AS(SELECT
CASE WHEN null1.dept_id IS NULL THEN full1.dept_id ELSE null1.dept_id END,
CASE WHEN null1.dept_name IS NULL THEN full1.dept_name ELSE null1.dept_name END,
first_name,last_name,salary
FROM null1 RIGHT JOIN full1 ON null1.dept_id=full1.dept_id)
SELECT * from nulled) B;
图 10. 空值查询的结果 (Mohammed Kamil Khan, CC BY-SA 4.0)
空值查询在 null1 表的 dept_id 和 dept_name 列中遇到的空值上使用 CASE WHEN,并将它们替换为 full1 表中的相应值。 现在我需要做的就是将图 7 和图 10 中获得的表格应用 UNION。这可以通过使用 WITH 声明上一个代码中的最后一个查询,然后使用 UNION 将其与 null1 结合来实现。
SELECT * FROM (WITH null1 AS (select A.dept_id, A.dept_name, A.first_name, A.last_name, A.salary
from (SELECT * FROM (
SELECT department.dept_id, department.dept_name, employee.first_name, employee.last_name,
employee.salary, DENSE_RANK() OVER (PARTITION BY employee.dept_id ORDER BY employee.salary DESC) AS Rank1
FROM employee INNER JOIN department
ON employee.dept_id=department.dept_id) AS k
WHERE rank1=4)A),
full1 AS (SELECT dept_id, dept_name FROM department WHERE dept_id NOT IN (SELECT dept_id FROM null1 WHERE dept_id IS NOT null)),
nulled AS(SELECT
CASE WHEN null1.dept_id IS NULL THEN full1.dept_id ELSE null1.dept_id END,
CASE WHEN null1.dept_name IS NULL THEN full1.dept_name ELSE null1.dept_name END,
first_name,last_name,salary
FROM null1 RIGHT JOIN full1 ON null1.dept_id=full1.dept_id)
SELECT * from null1
UNION
SELECT * FROM nulled
ORDER BY dept_id)
B;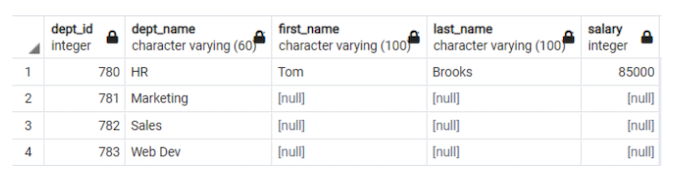
图 11. 最终结果 (Mohammed Kamil Khan, CC BY-SA 4.0)
现在我可以从图 11 中推断出,市场营销部、销售部和 Web 开发部是没有员工获得第四高薪水的部门。





评论已关闭。