

在本系列中,我正在开发几个脚本来帮助清理我的音乐收藏。在上一篇文章中,我们使用了为分析音乐文件的目录和子目录而创建的框架,检查以确保每个专辑都有一个 cover.jpg 文件,并记录任何不是 FLAC、MP3 或 OGG 的其他文件。
我发现了一些显然可以删除的文件——我看到零星的 foo 文件——以及一堆 PDF、PNG 和 JPG 文件,它们是专辑封面。考虑到这一点,并考虑到清理任务,我提供了一个改进的脚本,该脚本使用 Groovy map 来记录文件名及其出现次数,并以 CSV 格式打印出来。
开始使用 Groovy 进行分析
如果您还没有阅读过本系列的前三篇文章,请在继续之前阅读
它们将确保您了解我的音乐目录的预期结构、该文章中创建的框架以及如何拾取 FLAC、MP3 和 OGG 文件。在本文中,我演示了如何删除专辑目录中不需要的文件。
框架和专辑文件分析部分
从代码开始。和以前一样,我在脚本中加入了注释,这些注释反映了我通常为自己留下的(相对简短的)“注释笔记”
1 // Define the music libary directory
2 // def musicLibraryDirName = '/var/lib/mpd/music'
3 // Define the file name accumulation map
4 def fileNameCounts = [:]
5 // Print the CSV file header
6 println "filename|count"
7 // Iterate over each directory in the music libary directory
8 // These are assumed to be artist directories
9 new File(musicLibraryDirName).eachDir { artistDir ->
10 // Iterate over each directory in the artist directory
11 // These are assumed to be album directories
12 artistDir.eachDir { albumDir ->
13 // Iterate over each file in the album directory
14 // These are assumed to be content or related
15 // (cover.jpg, PDFs with liner notes etc)
16 albumDir.eachFile { contentFile ->
17 // Analyze the file
18 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
19 // nothing to do here
20 } else if (contentFile.name == 'cover.jpg') {
21 // don't need to do anything with cover.jpg
22 } else {
23 def fn = contentFile.name
24 if (contentFile.isDirectory())
25 fn += '/'
26 fileNameCounts[fn] = fileNameCounts.containsKey(fn) ? fileNameCounts[fn] + 1 : 1
27 }
28 }
29 }
30 }
31 // Print the file name counts
32 fileNameCounts.each { key, value ->
33 println "$key|$value"
34 }这是对原始框架进行的一组非常简单的修改。
第 3-4 行定义了 fileNameCount,这是一个用于记录文件名计数的 map。
第 17-27 行分析文件名。我避免任何以 .flac、.mp3 或 .ogg 结尾的文件以及 cover.jpg 文件。
第 23-26 行记录文件名(作为 fileNameCounts 的键)和计数(作为值)。如果文件实际上是一个目录,我会在末尾添加一个 / 以帮助在删除过程中处理它。请注意第 26 行,Groovy map,就像 Java map 一样,需要在递增值之前检查键是否存在,这与例如 awk 编程语言不同。
就这样!
我按如下方式运行它
$ groovy TagAnalyzer4.groovy > tagAnalysis4.csv然后我通过导航到 工作表 菜单并选择 从文件插入工作表,将生成的 CSV 加载到 LibreOffice 电子表格中。我将分隔符设置为 &$124;。
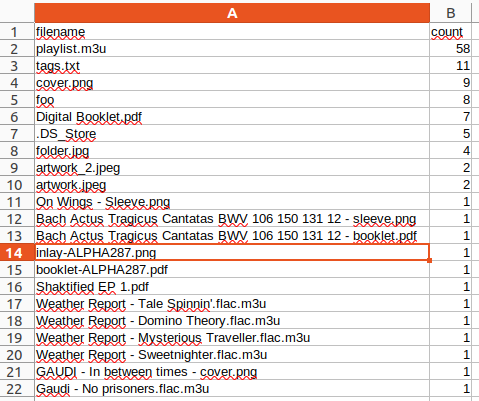
(Chris Hermansen,CC BY-SA 4.0)
我已经按 count 列的降序对此进行了排序,以强调重复出现的文件。还要注意第 17-20 行,一堆 M3U 文件,它们引用专辑的名称,可能是由某些好意的翻录程序创建的。我还看到,在更下方(未显示),像 fix 和 fixtags.sh 这样的文件,证明了之前为清理某些问题所做的努力,并在过程中留下了其他垃圾。我使用 find 命令行实用程序来摆脱其中的一些文件,类似于
$ find . \( -name \*.m3u -o -name tags.txt -o -name foo -o -name .DS_Store \
-o -name fix -o -name fixtags.sh \) -exec rm {} \;我想我也可以使用另一个 Groovy 脚本来做到这一点。也许下次吧。







评论已关闭。