

在我之前的文章中,我创建了一个框架,用于分析音乐文件的目录和子目录,使用了扩展和简化了 java.File 并简化其使用的 groovy.File 类。在本文中,我使用开源的 JAudiotagger 库来分析音乐目录和子目录中音乐文件的标签。如果您打算继续学习,请务必阅读本系列的第一篇文章。
安装 Java 和 Groovy
Groovy 基于 Java,需要安装 Java。 您 Linux 发行版的存储库中可能包含最新且不错的 Java 和 Groovy 版本。 Groovy 也可以直接从 Apache 基金会网站安装。 Linux 用户的另一个不错的选择是 SDKMan,它可用于获取多个版本的 Java、Groovy 和许多其他相关工具。 对于本文,我使用 SDK 发布的版本:
- Java: OpenJDK 11 的 11.0.12-open 版本
- Groovy: 3.0.8 版本
回到问题
在我小心翼翼地翻录我的 CD 收藏并越来越多地购买数字下载的大约 15 年时间里,我发现翻录程序和数字音乐下载供应商在标记音乐文件方面各不相同。 有时,我的文件缺少对音乐播放器有用的标签,例如 ALBUMSORT。 有时,这意味着我的文件充满了我不关心的标签,例如 MUSICBRAINZ_DISCID,这会导致某些音乐播放器以晦涩的方式更改演示顺序,因此一个专辑看起来像多个专辑,或者以奇怪的顺序排序。
鉴于我拥有近 10,000 首曲目,分布在近 700 张专辑中,如果我的音乐播放器能够以合理易懂的顺序显示我的收藏,那将是相当不错的。 因此,本系列的最终目标是创建一些有用的脚本来帮助识别缺失或不寻常的标签,并促进创建工作计划以解决标签问题。 此特定脚本分析音乐文件的标签,并创建一个 CSV 文件,我可以将其加载到 LibreOffice 或 OnlyOffice 中以查找问题。 它不会查看丢失的 cover.jpg 文件,也不会显示包含其他文件的专辑子子目录,因为这与音乐文件级别无关。
我的 Groovy 框架 + JAudiotagger
再次,从代码开始。 和以前一样,我已将注释合并到脚本中,以反映我通常为自己留下的(相对简短的)“注释”。
1 @Grab('net.jthink:jaudiotagger:3.0.1')
2 import org.jaudiotagger.audio.*
3 def logger = java.util.logging.Logger.getLogger('org.jaudiotagger');
4 logger.setLevel(java.util.logging.Level.OFF);
5 // Define the music library directory
6 def musicLibraryDirName = '/var/lib/mpd/music'
7 // These are the music file tags we are happy to see
8 // Some tags can occur more than once in a given file
9 def wantedFieldIdSet = ['ALBUM', 'ALBUMARTIST',
10 'ALBUMARTISTSORT', 'ARTIST', 'ARTISTSORT',
11 'COMPOSER', 'COMPOSERSORT', 'COVERART', 'DATE',
12 'GENRE', 'TITLE', 'TITLESORT', 'TRACKNUMBER',
13 'TRACKTOTAL', 'VENDOR', 'YEAR'] as LinkedHashSet
14 // Print the CSV file header
15 print "artistDir|albumDir|contentFile"
16 print "|${wantedFieldIdSet*.toLowerCase().join('|')}"
17 println "|other tags"
18 // Iterate over each directory in the music libary directory
19 // These are assumed to be artist directories
20 new File(musicLibraryDirName).eachDir { artistDir ->
21 // Iterate over each directory in the artist directory
22 // These are assumed to be album directories
23 artistDir.eachDir { albumDir ->
24 // Iterate over each file in the album directory
25 // These are assumed to be content or related
26 // (cover.jpg, PDFs with liner notes etc)
27 albumDir.eachFile { contentFile ->
28 // Initialize the counter map for tags we like
29 // and the list for unwanted tags
30 def fieldKeyCounters = wantedFieldIdSet.collectEntries { e ->
31 [(e): 0]
32 }
33 def unwantedFieldIds = []
34 // Analyze the file and print the analysis
35 if (contentFile.name ==~ /.*\.(flac|mp3|ogg)/) {
36 def af = AudioFileIO.read(contentFile)
37 af.tag.fields.each { tagField ->
38 if (tagField.id in wantedFieldIdSet)
39 fieldKeyCounters[tagField.id]++
40 else
41 unwantedFieldIds << tagField.id
42 }
43 print "${artistDir.name}|${albumDir.name}|${contentFile.name}"
44 wantedFieldIdSet.each { fieldId ->
45 print "|${fieldKeyCounters[fieldId]}"
46 }
47 println "|${unwantedFieldIds.join(',')}"
48 }
49 }
50 }
51 }
第 1 行是那些令人敬畏的 Groovy 功能之一,它极大地简化了生活。 事实证明,JAudiotagger 的优秀开发人员在 Maven 中央存储库上提供了已编译的版本。 在 Java 中,这需要一些 XML 仪式和配置。 使用 Groovy,我只需使用 @Grab 注释,Groovy 会在后台处理其余的事情。
第 2 行从 JAudiotagger 库导入相关的类文件。
第 3-4 行配置 JAudiotagger 库以关闭日志记录。 在我自己的实验中,默认级别非常冗长,并且使用 JAudiotagger 的任何脚本的输出都充满了日志记录信息。 这效果很好,因为 Groovy 将脚本构建到一个静态主类中。 我相信我不是唯一一个在某个实例方法中配置记录器,却发现配置在实例方法返回后被垃圾回收的人。
第 5-6 行来自第 1 部分中介绍的框架。
第 7-13 行创建一个 LinkedHashSet,其中包含我希望每个文件中都包含的标签列表(或者至少,我可以接受每个文件中都包含的标签)。 我在这里使用 LinkedHashSet,以便对标签进行排序。
现在是指出我现在使用的术语与 JAudiotagger 库中的类定义之间存在差异的好时机。 我一直称之为“标签”的是 JAudiotagger 称之为 org.jaudiotagger.tag.TagField 实例。 这些实例存在于 org.jaudiotagger.tag.Tag 的实例中。 因此,从 JAudiotagger 的角度来看,“标签”是“标签字段”的集合。 在本文的其余部分中,我将遵循他们的命名约定。
此字符串集合反映了一些使用 metaflac 进行的 先前的挖掘。 最后,值得一提的是,JAudiotagger 的 org.jaudiotagger.tag.FieldKey 使用“_”分隔字段键中的单词,这似乎与 org.jaudiotagger.tag.Tag.getFields() 返回的字符串不兼容,因此我不使用 FieldKey。
第 14-17 行打印 CSV 文件标头。 请注意使用 Groovy 的 *. 展开运算符将 toLowerCase() 应用于 wantedFieldIdSet 的每个(大写)字符串元素。
第 18-27 行来自第 1 部分中介绍的框架,下降到找到音乐文件的子子目录中。
第 28-32 行初始化所需字段的计数器映射。 我在这里使用计数器是因为某些标签字段在给定文件中可以多次出现。 请注意使用 wantedFieldIdSet.collectEntries 通过使用集合元素作为键来构建映射(键值 e 括在括号中,因为它必须被评估)。 我在 本文中更详细地解释了 Groovy 中的映射。
第 33 行初始化一个列表,用于累积不需要的标签字段 ID。
第 34-48 行分析找到的任何 FLAC、MP3 或 OGG 音乐文件
- 第 35 行使用 Groovy 匹配运算符
==~和“斜杠”正则表达式来检查文件名模式; - 第 36 行使用
org.jaudiotagger.AudioFileIO.read()将音乐文件元数据读入变量 af - 第 37-48 行循环访问元数据中找到的标签字段
- 第 37 行使用 Groovy 的
each()方法来迭代由af.tag.getFields()返回的标签字段列表,在 Groovy 中可以缩写为af.tag.fields - 第 38-39 行统计任何出现的所需标签字段 ID
- 第 40-41 行将不需要的标签字段 ID 的出现附加到不需要的列表中
- 第 43-47 行打印出计数和不需要的字段(如果有)
- 第 37 行使用 Groovy 的
就这样!
通常,我会按如下方式运行它
$ groovy TagAnalyzer2.groovy > tagAnalysis2.csv
$然后我将生成的 CSV 加载到电子表格中。 例如,使用 LibreOffice Calc,我转到工作表菜单并选择从文件插入工作表。 我将分隔符字符设置为 |。 在我的例子中,结果看起来像这样
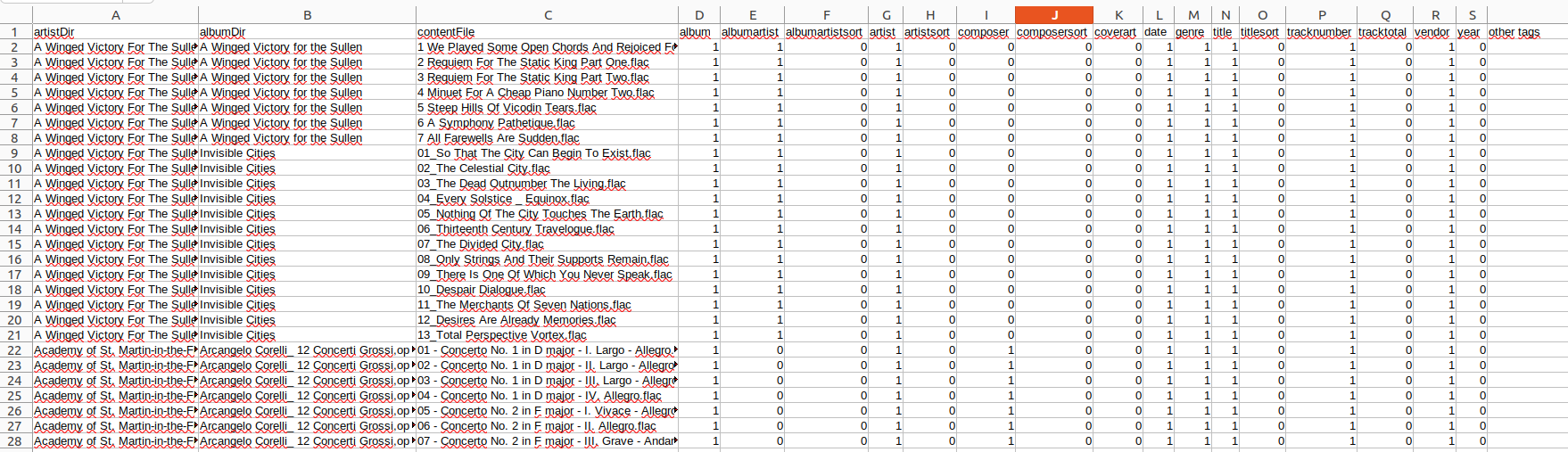
(Chris Hermansen, CC BY-SA 4.0)
我喜欢将 ALBUMARTIST 定义为 ARTIST,以便某些音乐播放器将专辑中的文件分组在一起,以便个人曲目上的艺术家有所不同。 这发生在合辑专辑中,但也发生在一些有嘉宾艺术家的专辑中,其中 ARTIST 字段可能说例如“Tony Bennett 和 Snoop Dogg”(我编造的。我想。)上面显示的电子表格中的第 22 行及之后未指定专辑艺术家,因此我可能希望在将来修复它。
这是最后一列显示不需要的字段 ID 的样子
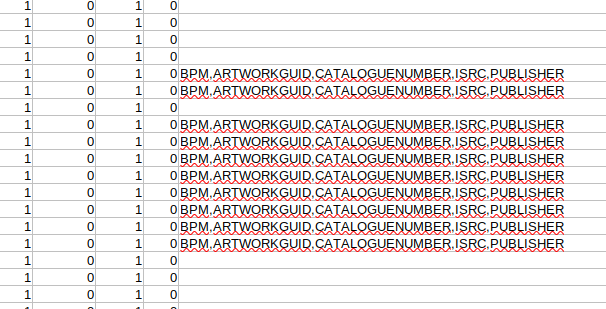
(Chris Hermansen, CC BY-SA 4.0)
请注意,这些标签可能有些趣味,因此修改了“需要”列表以包含它们。 我将设置某种脚本来删除字段 ID BPM、ARTWORKGUID、CATALOGUENUMBER、ISRC 和 PUBLISHER。
下一步
在下一篇文章中,我将从曲目退后一步,检查 cover.jpg 和其他非音乐文件是否位于艺术家子目录和专辑子子目录中。





评论已关闭。