

Kubernetes 数据库操作符对于构建可扩展的数据库服务器作为数据库 (DB) 集群非常有用。但是,由于您必须创建表示为 YAML 文件的新工件,因此将现有数据库迁移到 Kubernetes 需要大量的手工工作。本文介绍了一个名为 Konveyor Tackle-DiVA-DOA (数据密集型有效性分析器 - 数据库操作符适配) 的新型开源工具。它通过以数据为中心的代码分析,自动生成用于数据库操作符迁移的就绪部署工件。
什么是 Tackle-DiVA-DOA?
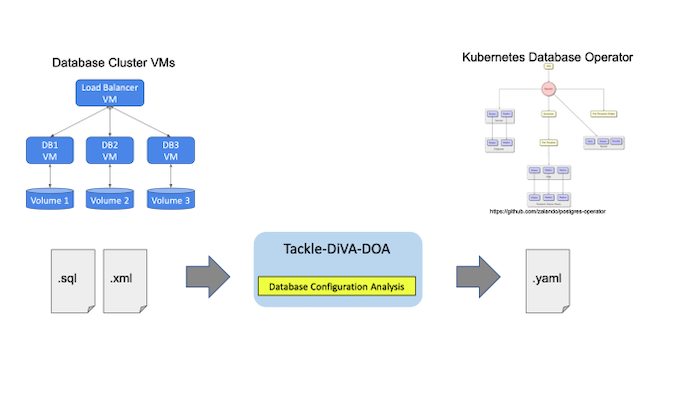
Tackle-DiVA-DOA (简称 DOA) 是 Konveyor Tackle 中的一个开源的以数据为中心的数据库配置分析工具。它导入目标数据库配置文件 (例如 SQL 和 XML),并为数据库迁移到操作符 (例如 Zalando Postgres Operator) 生成一组 Kubernetes 工件。
(Yasuharu Katsuno 和 Shin Saito, CC BY-SA 4.0)
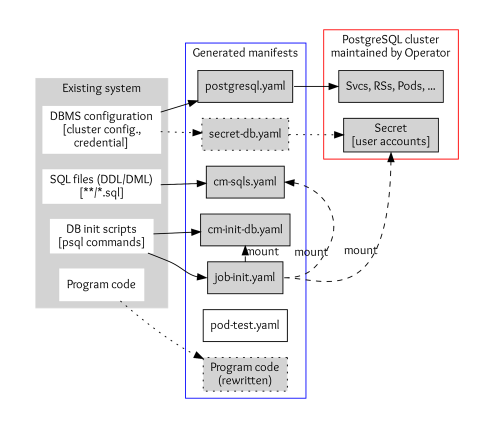
DOA 查找并分析使用数据库管理系统 (DBMS) 的现有系统的设置。然后,它生成 Kubernetes 和 Postgres 操作符的清单 (YAML 文件),用于部署等效的 DB 集群。
(Yasuharu Katsuno 和 Shin Saito, CC BY-SA 4.0)
应用程序的数据库设置包括 DBMS 配置、SQL 文件、DB 初始化脚本和用于访问 DB 的程序代码。
- DBMS 配置 包括 DBMS 参数、集群配置和凭据。如果您需要自定义凭据,DOA 将配置存储到
postgres.yaml,并将密钥存储到secret-db.yaml。
- SQL 文件 用于定义和初始化数据库中的表、视图和其他实体。这些存储在 Kubernetes ConfigMap 定义
cm-sqls.yaml中。
- 数据库初始化脚本 通常创建数据库和模式,并授予用户访问 DB 实体的权限,以便 SQL 文件可以正确工作。DOA 尝试从脚本和文档中查找初始化要求,如果找不到,则会猜测。结果也将存储在名为
cm-init-db.yaml的 ConfigMap 中。
- 访问数据库的代码,例如主机和数据库名称,在某些情况下嵌入在程序代码中。这些代码将被重写以与迁移后的 DB 集群一起工作。
教程
DOA 预计在容器内运行,并附带一个用于构建其镜像的脚本。确保您的环境中安装了 Docker 和 Bash,然后按如下方式运行构建脚本
$ cd /tmp
$ git clone https://github.com/konveyor/tackle-diva.git
$ cd tackle-diva/doa
$ bash util/build.sh
…
docker image ls diva-doa
REPOSITORY TAG IMAGE ID CREATED SIZE
diva-doa 2.2.0 5f9dd8f9f0eb 14 hours ago 1.27GB
diva-doa latest 5f9dd8f9f0eb 14 hours ago 1.27GB这将构建 DOA 并打包为容器镜像。现在 DOA 即可使用。
下一步执行捆绑的 run-doa.sh 包装器脚本,该脚本运行 DOA 容器。指定目标数据库应用程序的 Git 存储库。此示例使用 TradeApp 应用程序中的 Postgres 数据库。您可以对输出文件的位置使用 -o 选项,对数据库初始化脚本的名称使用 -i 选项
$ cd /tmp/tackle-diva/doa
$ bash run-doa.sh -o /tmp/out -i start_up.sh \
https://github.com/saud-aslam/trading-app
[OK] successfully completed.
将创建 /tmp/out/ 目录和 /tmp/out/trading-app 目录,后者是包含目标应用程序名称的目录。在本例中,应用程序名称为 trading-app,它是 GitHub 存储库名称。生成的工件 (YAML 文件) 也将在应用程序名称目录下生成
$ ls -FR /tmp/out/trading-app/
/tmp/out/trading-app/:
cm-init-db.yaml cm-sqls.yaml create.sh* delete.sh* job-init.yaml postgres.yaml test/
/tmp/out/trading-app/test:
pod-test.yaml每个 YAML 文件的前缀表示该文件定义的资源类型。例如,每个 cm-*.yaml 文件定义一个 ConfigMap,而 job-init.yaml 定义一个 Job 资源。此时,secret-db.yaml 尚未创建,DOA 使用 Postgres 操作符自动生成的凭据。
现在您拥有在 Kubernetes 实例上部署 PostgreSQL 集群所需的资源定义。您可以使用实用程序脚本 create.sh 部署它们。或者,您可以使用 kubectl create 命令
$ cd /tmp/out/trading-app
$ bash create.sh # or simply “kubectl apply -f .”
configmap/trading-app-cm-init-db created
configmap/trading-app-cm-sqls created
job.batch/trading-app-init created
postgresql.acid.zalan.do/diva-trading-app-db created
将创建 Kubernetes 资源,包括 postgresql (Postgres 操作符创建的数据库集群的资源)、service、rs、pod、job、cm、secret、pv 和 pvc。例如,您可以看到四个名为 trading-app-* 的数据库 pod,因为数据库实例的数量在 postgres.yaml 中定义为四个。
$ kubectl get all,postgresql,cm,secret,pv,pvc
NAME READY STATUS RESTARTS AGE
…
pod/trading-app-db-0 1/1 Running 0 7m11s
pod/trading-app-db-1 1/1 Running 0 5m
pod/trading-app-db-2 1/1 Running 0 4m14s
pod/trading-app-db-3 1/1 Running 0 4m
NAME TEAM VERSION PODS VOLUME CPU-REQUEST MEMORY-REQUEST AGE STATUS
postgresql.acid.zalan.do/trading-app-db trading-app 13 4 1Gi 15m Running
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/trading-app-db ClusterIP 10.97.59.252 <none> 5432/TCP 15m
service/trading-app-db-repl ClusterIP 10.108.49.133 <none> 5432/TCP 15m
NAME COMPLETIONS DURATION AGE
job.batch/trading-app-init 1/1 2m39s 15m
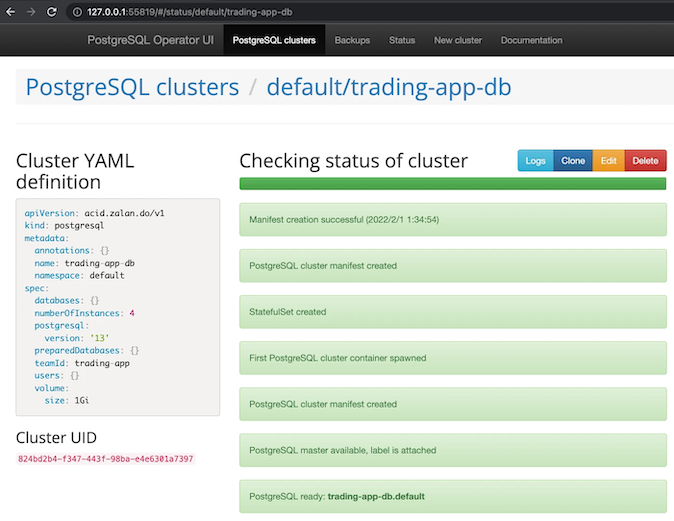
请注意,Postgres 操作符附带用户界面 (UI)。您可以在 UI 上找到创建的集群。您需要导出端点 URL 才能在浏览器上打开 UI。如果您使用 minikube,请执行以下操作
$ minikube service postgres-operator-ui
然后,会自动打开一个浏览器窗口,显示 UI。
(Yasuharu Katsuno 和 Shin Saito, CC BY-SA 4.0)
现在,您可以使用测试 pod 访问数据库实例。DOA 还生成了一个用于测试的 pod 定义。
$ kubectl apply -f /tmp/out/trading-app/test/pod-test.yaml # creates a test Pod
pod/trading-app-test created
$ kubectl exec trading-app-test -it -- bash # login to the pod
数据库主机名和访问 DB 的凭据已注入到 pod 中,因此您可以使用它们访问数据库。执行 psql 元命令以显示所有表和视图 (在数据库中)
# printenv DB_HOST; printenv PGPASSWORD
(values of the variable are shown)
# psql -h ${DB_HOST} -U postgres -d jrvstrading -c '\dt'
List of relations
Schema | Name | Type | Owner
--------+----------------+-------+----------
public | account | table | postgres
public | quote | table | postgres
public | security_order | table | postgres
public | trader | table | postgres
(4 rows)
# psql -h ${DB_HOST} -U postgres -d jrvstrading -c '\dv'
List of relations
Schema | Name | Type | Owner
--------+-----------------------+------+----------
public | pg_stat_kcache | view | postgres
public | pg_stat_kcache_detail | view | postgres
public | pg_stat_statements | view | postgres
public | position | view | postgres
(4 rows)
测试完成后,从 pod 中注销并删除测试 pod
# exit
$ kubectl delete -f /tmp/out/trading-app/test/pod-test.yaml
最后,使用脚本删除创建的集群
$ bash delete.sh欢迎来到 Konveyor Tackle 世界!
要了解有关应用程序重构的更多信息,您可以查看 Konveyor Tackle 网站,加入社区,并在 GitHub 上访问源代码。







评论已关闭。