

在高速互联网时代,大多数大型信息系统都构建为分布式系统,组件在不同的机器上运行。这些系统的性能通常通过其吞吐量和响应时间来评估。当性能不佳时,由于不同子组件之间复杂的交互以及问题可能发生在通信路径上各个位置,因此调试这些系统具有挑战性。
在最快的网络上,分布式系统的性能受到主机生成、传输、处理和接收数据的能力的限制,而这又取决于其硬件和配置。如果可以使用网络基准测试运行的存储库来调整分布式系统的网络性能,并建议一组最有效地提高网络性能的硬件和操作系统参数子集,那会怎么样呢?
为了回答这个问题,我们的团队使用了 Pbench,这是一个由红帽性能工程团队开发的基准测试和性能分析框架。本文将逐步介绍我们确定最有效方法并在预测性性能调优工具中实施这些方法的过程。
提出的方法是什么?
给定网络基准测试运行的数据集,我们提出以下步骤来解决这个问题。
- 数据准备: 收集网络基准测试的配置信息、工作负载和性能结果;清理数据;并将其存储为易于使用的格式
- 查找重要特征: 选择操作系统和硬件参数的初始集合,并使用各种特征选择方法来识别重要参数
- 开发预测模型: 开发一种机器学习模型,该模型可以预测给定客户端和服务器系统以及工作负载的网络性能
- 推荐配置: 给定用户所需的网络性能,建议客户端和服务器的配置,该配置在数据库中具有最接近的性能,并提供数据显示结果潜在变化范围
- 评估: 使用交叉验证确定模型的有效性,并建议量化配置建议带来的改进的方法
我们使用 Pbench 收集了此项目的数据。如下图所示,Pbench 接受基准测试类型及其工作负载、要运行的性能工具以及要执行基准测试的主机作为输入。它输出所有主机的基准测试结果、工具结果和系统配置信息。
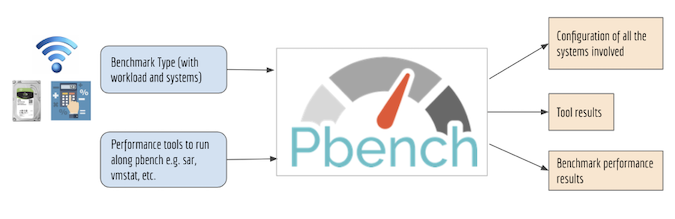
(Hifza Khalid, CC BY-SA 4.0)
在 Pbench 运行的不同基准测试脚本中,我们使用了使用 uperf 基准测试收集的数据。Uperf 是一种网络性能工具,它将工作负载的描述作为输入,并相应地生成负载以测量系统性能。
数据准备
Pbench 生成两个不相交的数据集。来自被测系统的配置数据存储在文件系统中。性能结果以及工作负载元数据被索引到 Elasticsearch 实例中。配置数据和性能结果之间的映射也存储在 Elasticsearch 中。为了与 Elasticsearch 中的数据交互,我们使用了 Kibana。使用这两个数据集,我们为每次基准测试运行组合了工作负载元数据、配置数据和性能结果。
查找重要特征
为了选择硬件规格和操作系统配置的初始集合,我们使用了性能调优配置指南和红帽专家的反馈。此步骤的目标是开始使用少量参数,并通过进一步分析对其进行改进。该集合基于几乎所有主要系统子组件的参数,包括硬件、内存、磁盘、网络、内核和 CPU。
选择初步特征集后,我们使用最常见的降维技术之一来消除冗余参数:删除具有恒定值的参数。虽然此步骤消除了一些参数,但鉴于系统信息和性能之间关系的复杂性,我们决定使用高级特征选择方法。
基于相关性的特征选择
相关性是用于查找两个特征之间关联的常用度量。如果特征线性相关,则它们具有高相关性。如果两个特征同时增加,则它们的相关性为 +1;如果它们同时减少,则为 -1。如果两个特征不相关,则它们的相关性接近于 0。
我们使用系统配置和目标变量之间的相关性来识别并进一步减少不重要的特征。为此,我们计算了配置参数和目标变量之间的相关性,并消除了所有值小于 |0.1| 的参数,|0.1| 是用于识别不相关对的常用阈值。
特征选择方法
由于相关性并不意味着因果关系,我们需要额外的特征选择方法来提取影响目标变量的参数。我们可以选择诸如递归特征消除之类的包装器方法和诸如 Lasso(最小绝对收缩和选择算子)和基于树的方法之类的嵌入式方法。
我们选择使用基于树的嵌入式方法,因为它们相对于包装器方法而言,具有简单性、灵活性和低计算成本的优点。这些方法具有内置的特征选择方法。在基于树的方法中,我们有三个选择:分类和回归树 (CART)、随机森林和 XGBoost。
我们通过取自三种基于树的方法获得的结果的并集,计算了客户端和服务器系统的最终重要特征集,如下表所示。
| 参数 | 客户端/服务器 | 描述 |
|---|---|---|
| Advertised_auto-negotation | 客户端 | 如果链接通告了自动协商 |
| CPU(s) | 服务器 | 机器上的逻辑核心数 |
| 网络速度 | 服务器 | 以太网设备的速度 |
| 型号名称 | 客户端 | 处理器型号 |
| rx_dropped | 服务器 | 数据包在进入计算机堆栈后被丢弃 |
| 型号名称 | 服务器 | 处理器型号 |
| 系统类型 | 服务器 | 虚拟或物理系统 |
开发预测模型
对于此步骤,我们使用了随机森林 (RF) 预测模型,因为它已知比 CART 性能更好,并且也更容易可视化。
随机森林 (RF) 构建多个决策树并将它们合并以获得更稳定和准确的预测。它以与 CART 相同的方式构建树,但为了确保树不相关以使其相互免受各自错误的影响,它使用了一种称为套袋法的技术。套袋法使用来自数据的有放回随机抽样来训练各个树。随机森林中的树与 CART 决策树中的树的另一个区别是为每次拆分选择的特征。CART 考虑每次拆分的每个可能的特征。但是,随机森林中的每棵树仅从特征的随机子集中选择。这导致随机森林树之间的变化更大。
RF 模型是分别针对两个目标变量构建的。
推荐配置
对于此步骤,给定所需的吞吐量和响应时间值以及感兴趣的工作负载,我们的工具会在基准测试运行数据库中搜索,以返回性能结果最接近用户要求的配置。它还会返回该运行的各种样本的标准偏差,表明实际结果的潜在变化。
评估
为了评估我们的预测模型,我们使用了重复的 K 折交叉验证技术。这是获得预测模型效率的准确估计的常用选择。
为了使用包含 9,048 个点的数据集评估预测模型,我们使用了等于 10 的 k 并重复了交叉验证方法三次。使用以下给出的两个指标计算准确率。
- R2 分数: 可以从自变量预测的因变量方差的比例。其值在 -1 和 1 之间变化。
- 均方根误差 (RMSE): 它测量估计值和实际值之间的平均平方差,并返回其平方根。
根据以上两个标准,以吞吐量和延迟作为目标变量的预测模型的结果如下
- 吞吐量(trans/秒)
- R2 分数:0.984
- RMSE:0.012
- 延迟(微秒)
- R2 分数:0.930
- RMSE:0.025
最终工具是什么样的?
我们在下图所示的工具中实现了我们的方法。该工具是用 Python 实现的。它接受包含基准测试运行信息的 CSV 文件作为输入,包括客户端和服务器配置、工作负载以及所需的延迟和吞吐量值。该工具使用此信息来预测用户客户端服务器系统的延迟和吞吐量结果。然后,它会在基准测试运行数据库中搜索,以返回性能结果最接近用户要求的配置,以及该运行的标准偏差。标准偏差是数据集的一部分,是使用一次迭代或运行的重复样本计算得出的。
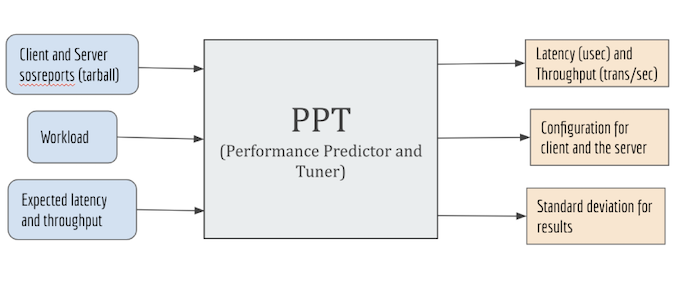
(Hifza Khalid, CC BY-SA 4.0)
这种方法有哪些挑战?
在解决这个问题时,我们遇到了几个挑战并解决了这些挑战。第一个主要挑战是收集基准测试数据,这需要学习 Elasticsearch 和 Kibana,这是红帽用于索引、存储和与 Pbench 数据交互的两种工业工具。另一个困难是处理数据中的不一致性、数据丢失以及索引数据中的错误。例如,基准测试运行的工作负载数据被索引到 Elasticsearch 中,但是一个关键的工作负载参数运行时丢失了。为此,我们不得不编写额外的代码以从存储在红帽服务器上的原始基准测试数据中访问它。
一旦我们克服了上述挑战,我们就花费了大量精力尝试几乎所有可用的特征选择技术,并弄清楚了网络性能的代表性硬件和操作系统参数集。理解这些技术的内部工作原理、它们的局限性和应用以及分析为什么它们中的大多数不适用于我们的案例是具有挑战性的。由于篇幅限制和时间不足,我们没有在本文中讨论所有这些方法。





评论已关闭。