

在数据分析的黄金时代,开源社区也不例外,也热衷于将一些大型、精美的数字放到演示幻灯片上。如果您掌握了生成一个经过良好分析的问题并适当执行的艺术,这些信息可以带来更大的价值。
您可能会期望我,一位 数据科学家,告诉您数据分析和自动化将为您的社区决策提供信息。 实际上恰恰相反。 使用数据分析来构建您现有的开源社区知识,整合他人,并发现未考虑到的潜在偏见和观点。 您可能是社区活动实施方面的专家,而您的同事则是所有代码方面的专家。 当你们每个人都在自己的知识范围内开发可视化时,你们都可以从该信息中受益。
让我们坦诚一点。 每个人都有成千上万的事情要处理,而且感觉一天的时间永远不够用。 如果获得关于您社区的答案需要数小时,您就不会定期(甚至永远不会)这样做。 花时间创建一个完全开发的可视化效果,可以让你跟上你关心的社区的不同方面。
随着“数据驱动”的压力越来越大,开源社区周围的大量信息可能既是祝福也是诅咒。 使用下面的方法,我将向您展示如何从数据堆中挑选出针。
你的视角是什么?
在考虑一个指标时,您必须考虑的第一件事是您想要提供的视角。 以下是您可以建立的一些概念。
提供信息 vs. 影响行动: 您社区中是否有不为人所知的领域? 您是否正在迈出第一步? 您是否正在决定一个特定的方向? 您是否正在衡量一项现有的举措?
暴露需要改进的领域 vs. 突出优势: 有时您会试图炒作您的社区并展示它有多么伟大,尤其是在试图展示业务影响或倡导您的项目时。 在告知您自己和社区时,您通常可以通过识别缺点来从您的指标中获得最大的价值。 突出优势并不是一个坏习惯,但要有时间和地点。 不要使用指标作为社区内部的啦啦队来告诉您每个人有多棒; 而是与外部人士分享,以获得认可或晋升。
社区和业务影响: 数字和数据是许多企业的语言。 这会使得倡导您的社区并真正展示其价值变得非常困难。 数据可以成为用他们的语言说话的一种方式,并展示他们想看到的东西,以便传达您的其余信息。 另一种观点是对开源的总体影响。 您的社区如何影响他人和生态系统?
这些并不总是非此即彼的观点。 适当的框架将有助于创建一个更深思熟虑的指标。
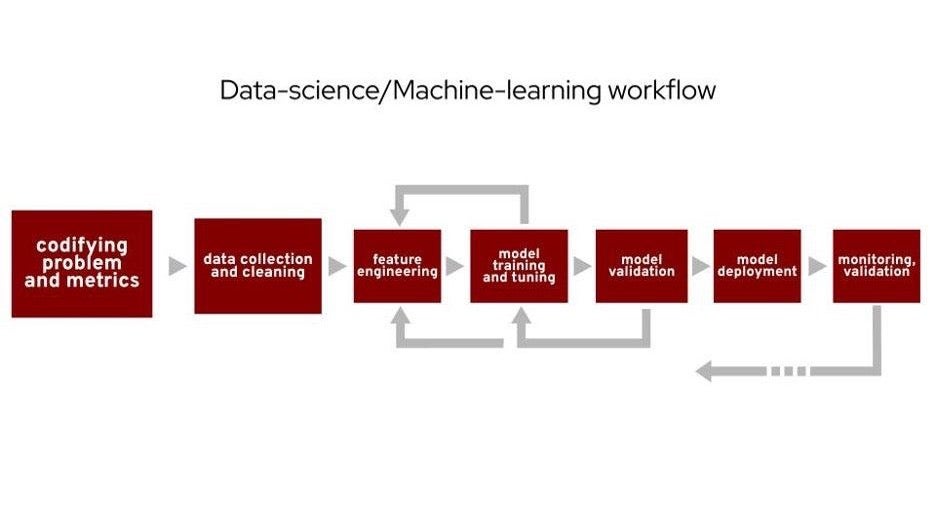
(Cali Dolfi,CC BY-SA 4.0)
人们在谈论一般数据科学或机器学习工作时,经常会描述这个工作流程的某个版本。 我将重点介绍第一步,即编纂问题和指标,并简要提及第二步。 从数据科学的角度来看,此演示文稿可以被视为此步骤的案例研究。 这一步有时会被忽略,但您分析的实际价值从这里开始。 您不会有一天醒来就知道要看什么。 首先要了解您想知道什么,以及您需要哪些数据才能达到深思熟虑地执行数据分析的真正目标。
开源中的 3 个数据分析用例
以下是您在开源数据分析过程中可能遇到的三种不同情况。
场景 1:当前数据分析
假设您开始沿着分析的道路前进,并且您已经知道您正在研究的内容通常对您/您的社区有用。 如何改进? 这里的想法是建立在“传统”开源社区分析的基础上。 假设您的数据表明您在项目的整个生命周期内总共有 120 位贡献者。 这是您可以放在幻灯片上的一个值,但您无法从中做出决定。 从仅仅拥有一个数字到拥有洞察力,开始采取渐进的步骤。 例如,您可以从相同的数据中将总贡献者的样本分解为活跃贡献者与漂移贡献者(在一定时间内没有贡献的贡献者)。
场景 2:社区活动影响评估
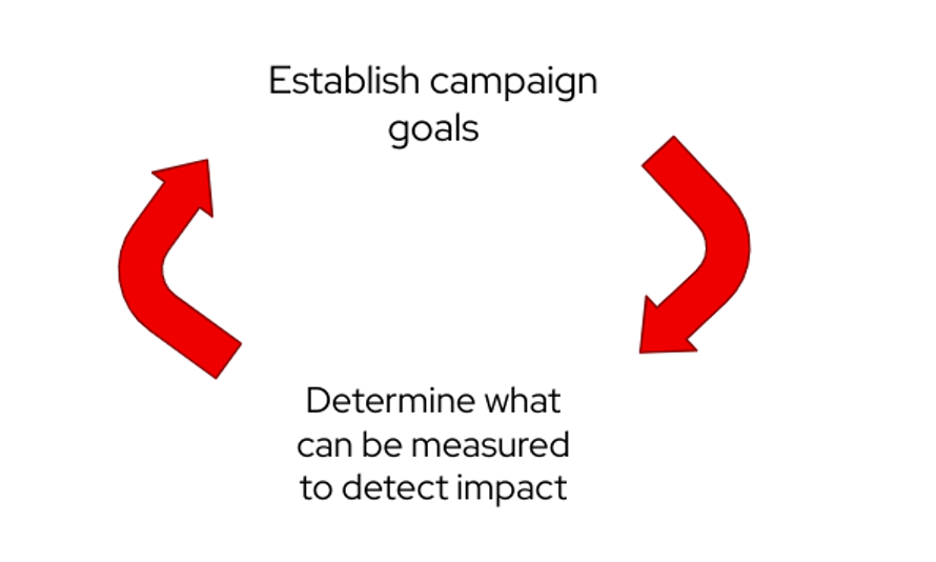
(Cali Dolfi,CC BY-SA 4.0)
考虑聚会、会议或任何社区外展活动。 您如何看待您的影响和目标? 这两个步骤实际上相互促进。 一旦您确定了活动目标,就确定可以衡量什么来检测效果。 这些信息有助于设定活动的目标。 当一项活动开始时,很容易陷入模糊而不是具体的计划的陷阱。
场景 3:形成新的分析领域以产生影响
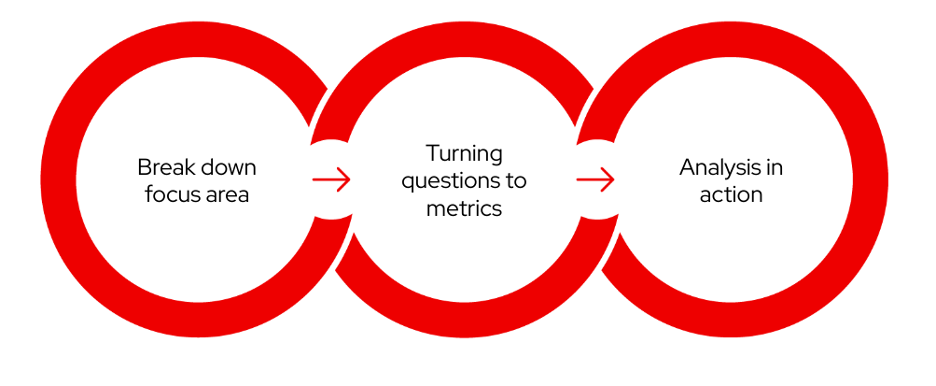
(Cali Dolfi,CC BY-SA 4.0)
当您从头开始进行数据分析时,会出现这种情况。 前面的示例是此工作流程的不同部分。 工作流程是一个持续的循环; 您可以随时进行改进或扩展。 从这个概念出发,以下是您应该完成的必要步骤。 在本文的后面部分,将有三个不同的示例说明这种方法在现实世界中是如何运作的。
步骤 1:分解重点领域和视角
首先,考虑一个魔术八号球 - 您可以问任何问题、摇晃并获得答案的玩具。 考虑您的分析领域。 如果您可以立即获得任何答案,那会是什么?
接下来,考虑数据。 从您的魔术八号球问题来看,哪些数据源可能与该问题或重点领域有关?
在数据上下文中可以回答哪些问题,以使您更接近您提出的魔术八号球问题? 重要的是要注意,如果您尝试将所有数据放在一起,则必须考虑所做的假设。
步骤 2:将问题转换为指标
以下是第一个步骤中每个子问题的过程
- 选择所需的特定数据点。
- 确定可视化以获得目标分析。
- 假设这些信息的影响。
接下来,引入社区以提供反馈并触发迭代开发过程。 这种协作部分可能是真正奇迹发生的地方。 当将一个概念带给某人,以您或他们无法想象的方式激发他们时,通常会产生最好的想法。
步骤 3:行动中的分析
在此步骤中,您开始研究您创建的指标或可视化的含义。
首先要考虑的是,该指标是否符合目前已知的关于社区的信息。
- 如果是是:是否存在针对结果做出的假设?
- 如果是否:您需要进一步调查,看看这是否可能是数据或计算问题,或者这只是以前对社区的误解。
一旦您确定您的分析足够稳定以进行推断,您就可以开始根据信息实施社区计划。 当您采纳分析来确定下一个最佳步骤时,您应该确定衡量该计划成功与否的具体方法。
现在,观察这些由您的指标提供的社区计划。 确定通过您先前建立的成功衡量标准是否可以观察到影响。 如果没有,请考虑以下事项
- 您是否衡量了正确的事情?
- 是否需要改变计划策略?
示例分析领域:新贡献者
我的魔术八号球问题是什么?
- 人们是否有让他们成为一致贡献者的体验?
我有哪些数据进入分析领域和魔术八号球问题?
- 存储库存在哪些贡献者活动,包括时间戳?
现在您有了信息和一个魔术八号球问题,将分析分解为子部分,并遵循每个子部分直至结束。 这个想法与上面的步骤 2 和 3 相关。
子问题 1:“人们是如何进入这个项目的?”
这个问题旨在了解新贡献者首先在做什么。
数据: GitHub 上关于随时间推移的首次贡献的数据(问题、PR、评论等)。
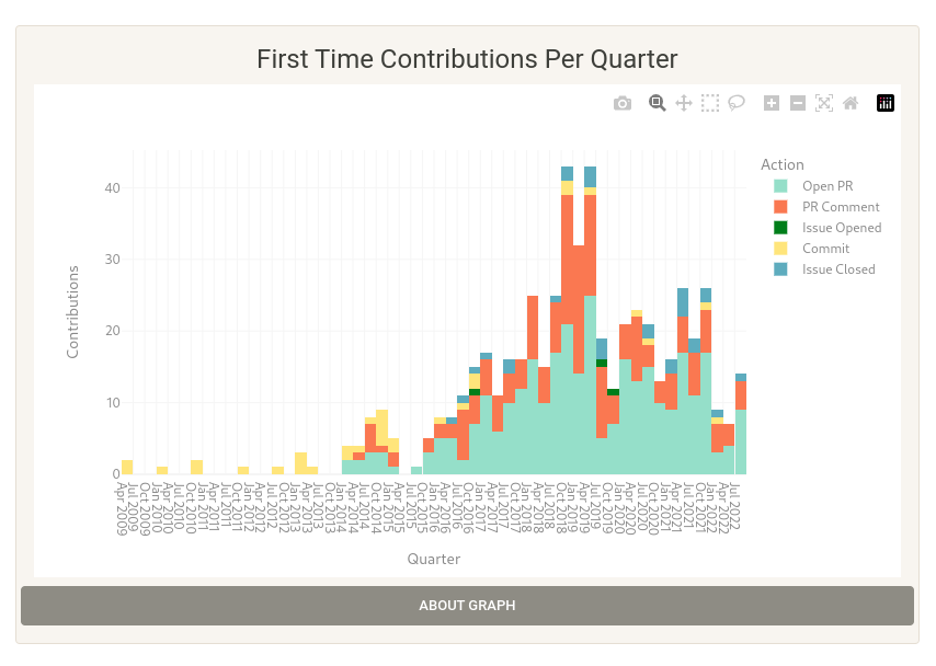
(Cali Dolfi,CC BY-SA 4.0)
可视化:按季度细分的首次贡献的条形图。
潜在扩展:在您与其他社区成员交谈后,进一步的检查会将信息按季度细分,并确定贡献者是回头客还是路人。 您可以看到人们在进入时正在做什么,以及这是否告诉您任何关于他们是否会留下的信息。
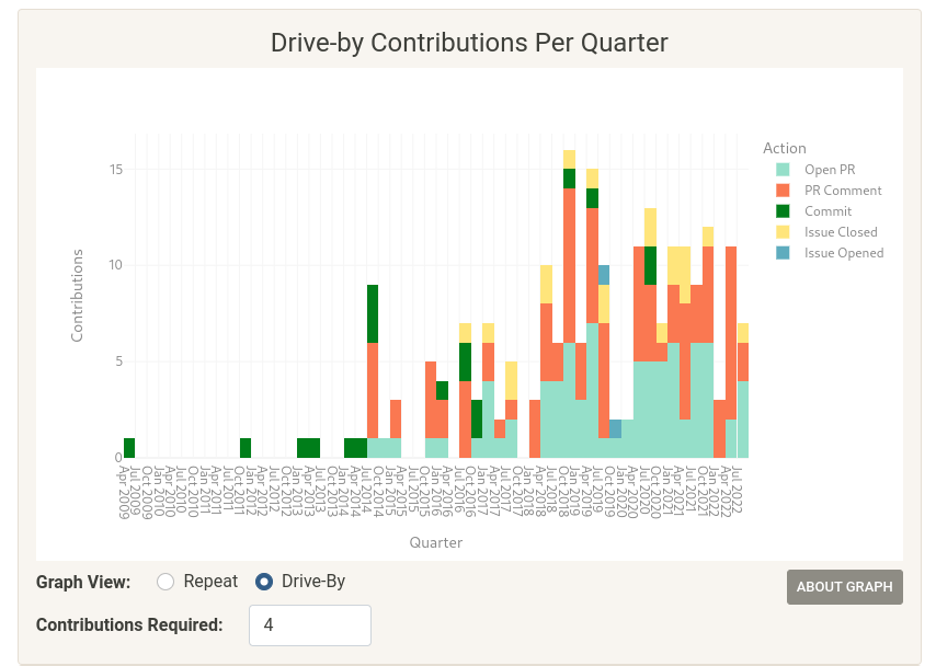
(Cali Dolfi,CC BY-SA 4.0)
由此信息告知的潜在行动
- 当前的文档是否能为最常见的首次贡献提供支持?是否能更好地支持这些贡献者,以及这是否有助于留住更多的贡献者?
- 是否存在某种贡献领域,它总体上并不常见,但对于重复贡献者来说却是一个好兆头?例如,PR(Pull Request)可能是重复贡献者的一个常见领域,但大多数人并不在这个领域工作。
行动项目
- 始终如一地标记 "good first issues"(适合新手的问题),并将这些问题链接到贡献文档。
- 为这些问题添加一个 PR buddy(PR伙伴)。
子问题 2:“我们的代码库真的依赖于一次性贡献者吗?”
数据:来自 GitHub 的贡献数据。
(Cali Dolfi,CC BY-SA 4.0)
可视化:“总贡献量:按一次性和重复贡献者分解。”
由此信息告知的潜在行动
- 这个比例是否达到了项目目标?大量工作是否由一次性贡献者完成?这是否是一种未充分利用的资源,并且项目是否没有尽到吸引他们的责任?
分析:经验教训
数字和数据分析不是“事实”。它们可以表达任何东西,所以在处理数据时,你内心的怀疑论者应该非常活跃。迭代过程才是带来价值的关键。你不希望你的分析成为一个“应声虫”。花时间退一步,评估你所做的假设。
如果一个指标只是指引你调查的方向,那就是一个巨大的胜利。你不可能看到或想到所有的事情。“兔子洞”可能是一件好事,并且对话的开始可以带你到一个新的地方。
有时你想要测量的东西并不存在,但你可能会获得有价值的细节。你不能假设你拥有所有的拼图碎片来得到你最初问题的确切答案。如果你开始强行寻找答案或解决方案,你可能会被你的假设带上一条危险的道路。允许分析的方向或目标发生变化,可能会让你获得比最初的想法更好的结果或洞察力。
数据是一种工具。它不是答案,但它可以汇集原本无法获得的见解和信息。将你想知道的内容分解成可管理的小块并在此基础上进行构建的方法是最重要的。
开源数据分析是一个很好的例子,说明了你必须对所有数据科学采取的谨慎态度。
- 主题领域的细微差别是最重要的。
- 完成 "询问/回答什么" 的过程通常被忽视。
- 知道问什么可能是最难的部分,当你提出一些有见地和创新性的东西时,它远比你选择的任何工具都重要。
如果你是一位没有数据科学经验的社区成员,正在寻找从哪里开始,我希望这些信息能让你了解你对这个过程有多么重要和有价值。你带来了社区的见解和观点。如果你是一位数据科学家或正在实施指标或可视化的人,你必须倾听周围的声音,即使你也是一个活跃的社区成员。有关数据科学的更多信息在本文末尾列出。
总结
使用上面的例子作为框架,建立你自己的开源项目的数据分析。对你的结果有很多问题要问,了解这些问题及其答案可以引导你的项目朝着令人兴奋和富有成果的方向发展。
更多关于数据科学的信息
请参考以下来源,以获取有关数据科学和为其提供数据的技术的更多信息





评论已关闭。