

当前加密货币的流行也包括加密货币的交易。去年,我写了一篇文章如何使用 Python 自动化您的加密货币交易 ,其中介绍了基于图形编程框架 Pythonic 的交易机器人的设置,这是我在业余时间开发的。当时,您仍然需要基于 x86 的桌面系统来运行 Pythonic。同时,我重新考虑了这个概念(基于 Web 的 GUI)。今天,可以在树莓派上运行 Pythonic,这主要有利于功耗,因为这样的交易机器人必须始终处于开启状态。
以前的文章仍然有效。如果您想基于旧版本的 Pythonic (0.x) 创建交易机器人,您可以使用 pip3 install Pythonic==0.19 安装它。
本文介绍了在树莓派上运行并执行基于 EMA 交叉策略 的交易算法的交易机器人的设置。
在您的树莓派上安装 Pythonic
在这里,我只简单介绍一下安装主题,因为您可以在我的上一篇文章 使用智能手机远程控制您的树莓派 中找到有关 Pythonic 的详细安装说明。简而言之:从 sourceforge.net 下载树莓派镜像并将其刷入 SD 卡。
PythonicRPI 镜像没有预安装的图形桌面,因此要继续,您应该能够访问编程 Web GUI (http : //PythonicRPI:7000/)

(Stephan Avenwedde, CC BY-SA 4.0)
示例代码
从 GitHub (直接下载链接) 下载交易机器人的示例代码并解压缩该压缩文件。该压缩文件包含三种不同的文件类型
\*.py-files:包含某些功能的实际实现current_config.json:此文件描述了配置的元素、元素之间的链接以及元素的变量配置jupyter/backtest.ipynb:用于回测的 Jupyter 笔记本jupyter/ADAUSD_5m.df:我在本例中使用的最小 OHLCV 数据集
使用绿色轮廓按钮,将 current_config.json 上传到树莓派。您只能上传有效的配置文件。使用黄色轮廓按钮,上传所有 \*.py 文件。

(Stephan Avenwedde, CC BY-SA 4.0)
\*.py 文件上传到 /home/pythonic/Pythonic/executables ,而 current_config.json 上传到 /home/pythonic/Pythonic/current_config.json。上传 current_config.json 后,您应该看到如下屏幕
(Stephan Avenwedde, CC BY-SA 4.0)
现在我将逐步介绍交易机器人的每个部分。
数据采集
与上一篇文章一样,我从数据采集开始

(Stephan Avenwedde, CC BY-SA 4.0)
数据采集可以在 Area 2 选项卡上找到,并且独立于机器人的其余部分运行。它实现了以下功能
- AcqusitionScheduler:每五分钟触发后续元素
- OHLCV_Query:准备 OHLCV 查询方法
- KrakenConnector:与 Kraken 加密货币交易所建立连接
- DataCollector:收集和处理新的 OHLCV 数据
DataCollector 获取带有前缀时间戳的 OHLCV 数据的 Python 列表,并将其转换为 Pandas DataFrame。 Pandas 是一个流行的用于数据分析和操作的库。 DataFrame 是任何类型数据的基本类型,可以对其应用算术运算。
DataCollector (generic_pipe_3e059017.py)的任务是从文件加载现有的 DataFrame,附加最新的 OHLCV 数据,然后将其保存回文件。
import time, queue
import pandas as pd
from pathlib import Path
try:
from element_types import Record, Function, ProcCMD, GuiCMD
except ImportError:
from Pythonic.element_types import Record, Function, ProcCMD, GuiCMD
class Element(Function):
def __init__(self, id, config, inputData, return_queue, cmd_queue):
super().__init__(id, config, inputData, return_queue, cmd_queue)
def execute(self):
df_in = pd.DataFrame(self.inputData, columns=['close_time', 'open', 'high', 'low', 'close', 'volume'])
df_in['close_time'] = df_in['close_time'].floordiv(1000) # remove milliseconds from timestamp
file_path = Path.home() / 'Pythonic' / 'executables' / 'ADAUSD_5m.df'
try:
# load existing dataframe
df = pd.read_pickle(file_path)
# count existing rows
n_row_cnt = df.shape[0]
# concat latest OHLCV data
df = pd.concat([df,df_in], ignore_index=True).drop_duplicates(['close_time'])
# reset the index
df.reset_index(drop=True, inplace=True)
# calculate number of new rows
n_new_rows = df.shape[0] - n_row_cnt
log_txt = '{}: {} new rows written'.format(file_path, n_new_rows)
except Exception as e:
log_txt = 'File error - writing new one'
df = df_in
# save dataframe to file
df.to_pickle(file_path)
logInfo = Record(None, log_txt)
self.return_queue.put(logInfo)
由于 OHLCV 数据也以 5 分钟为间隔,因此每满 5 分钟执行一次此代码。
默认情况下,OHLCV_Query 元素仅下载最新期间的数据集。为了获得一些用于开发交易算法的数据,右键单击 OHLCV_Query 元素以打开配置,将 Limit 设置为 500,然后触发 AcquisitionScheduler。 这会导致下载 500 个 OHLCV 值

(Stephan Avenwedde, CC BY-SA 4.0)
交易策略
我们的交易策略将是流行的 EMA 交叉策略。 EMA 指标是过去 n 个收盘价的加权移动平均值,它为最近的价格数据赋予更高的权重。 您计算两个 EMA 系列,一个用于较长的周期(例如,n = 21,蓝线),一个用于较短的周期(例如,n = 10,黄线)。

(Stephan Avenwedde, CC BY-SA 4.0)
当短期 EMA 向上穿过长期 EMA 时,机器人应下达买入订单(绿色圆圈)。 当短期 EMA 向下穿过长期 EMA 时,机器人应下达卖出订单(橙色圆圈)。
使用 Jupyter 进行回测
GitHub (直接下载链接) 上的示例代码还包含一个 Jupyter Notebook 文件 (backtesting.ipynb),您可以使用它来测试和开发交易算法。
注意: Pythonic 树莓派镜像上未预安装 Jupyter。 您也可以将其安装在树莓派上或将其安装在您的普通 PC 上。 我建议后者,因为您将进行一些数字运算,这在普通的 x86 CPU 上要快得多。
启动 Jupyter 并打开笔记本。 确保有一个由 DataCollector 下载的 DataFrame 可用。 使用 Shift+Enter,您可以单独执行每个单元格。 执行前三个单元格后,您应该获得如下输出

(Stephan Avenwedde, CC BY-SA 4.0)
现在计算 EMA-10 和 EMA-21 值。 幸运的是,pandas 为您提供了 ewm 函数,该函数完全可以满足需求。 EMA 值作为单独的列添加到 DataFrame 中

(Stephan Avenwedde, CC BY-SA 4.0)
要确定是否满足买入或卖出条件,您必须考虑以下四个变量
- emaLong0:当前的长期 (ema-21) EMA 值
- emaLong1:上一个长期 (ema-21) EMA 值(emaLong0 之前的值)
- emaShort0:当前的短期 (ema-10) EMA 值
- emaShort1:上一个短期 (ema-10) EMA 值(emaShort0 之前的值)
当出现以下情况时,满足买入条件

(Stephan Avenwedde, CC BY-SA 4.0)
在 Python 代码中
emaLong1 > emaShort1 and emaShort0 > emaLong0在以下情况下满足卖出条件

(Stephan Avenwedde, CC BY-SA 4.0)
在 Python 代码中
emaShort1 > emaLong1 and emaLong0 > emaShort0为了测试 DataFrame 并评估您可以获得的可能利润,您可以迭代每一行并测试这些条件,或者,采用更智能的方法,使用 Pandas 中的内置方法将数据集过滤到仅相关的行。
在底层,Pandas 使用 NumPy,这是在数组上进行快速高效数据操作的首选方法。 当然,这很方便,因为稍后将在带有 ARM CPU 的树莓派上使用。
为了清楚起见,以下示例中使用示例中的 DataFrame (ADAUSD_5m.df),仅包含 20 个条目。 以下代码根据条件 emaShort0 > emaLong0 附加一列布尔值

(Stephan Avenwedde, CC BY-SA 4.0)
感兴趣的地方是 False 切换到 True (买入)或 True 切换到 False 时。 要过滤它们,请将 diff 操作应用于 condition 列。 diff 操作计算当前行和上一行之间的差异。 就布尔值而言,结果为
- False
diffFalse = False - False
diffTrue = True - True
diffTrue = False - True
diffFalse = True
使用以下代码,您可以将 diff 操作作为过滤器应用于 condition 列,而无需修改它

(Stephan Avenwedde, CC BY-SA 4.0)
结果,您获得了所需的数据:第一行(索引 2)表示买入条件,第二行(索引 8)表示卖出条件。 既然您现在有一种提取相关数据的有效方法,您就可以计算可能的利润。
为此,您必须迭代各行并根据模拟交易计算可能的利润。 变量 bBought 保存您是否已经购买的状态,而 buyPrice 存储您在迭代之间购买的价格。 您还跳过第一个卖出指标,因为在您购买之前卖出是没有意义的。
profit = 0.0
buyPrice = 0.0
bBought = False
for index, row, in trades.iterrows():
# skip first sell-indicator
if not row['condition'] and not bBought:
continue
# buy-indication
if row['condition'] and not bBought:
bBought = True
buyPrice = row['close']
# sell-indication
if not row['condition'] and bBought:
bBought = False
sellPrice = row['close']
orderProfit = (sellPrice * 100) / buyPrice - 100
profit += orderProfit您的一次交易迷你数据集将为您提供以下利润

(Stephan Avenwedde, CC BY-SA 4.0)
注意: 如您所见,该策略会产生可怕的结果,因为您会以 2.5204 美元的价格购买,并以 2.5065 美元的价格出售,从而导致 0.55% 的损失(不包括订单费用)。 但是,这是一个真实场景:一种策略并不适用于每种场景。 您需要找到最有希望的参数(例如,通常使用每小时的 OHLCV 数据更有意义)。
实施
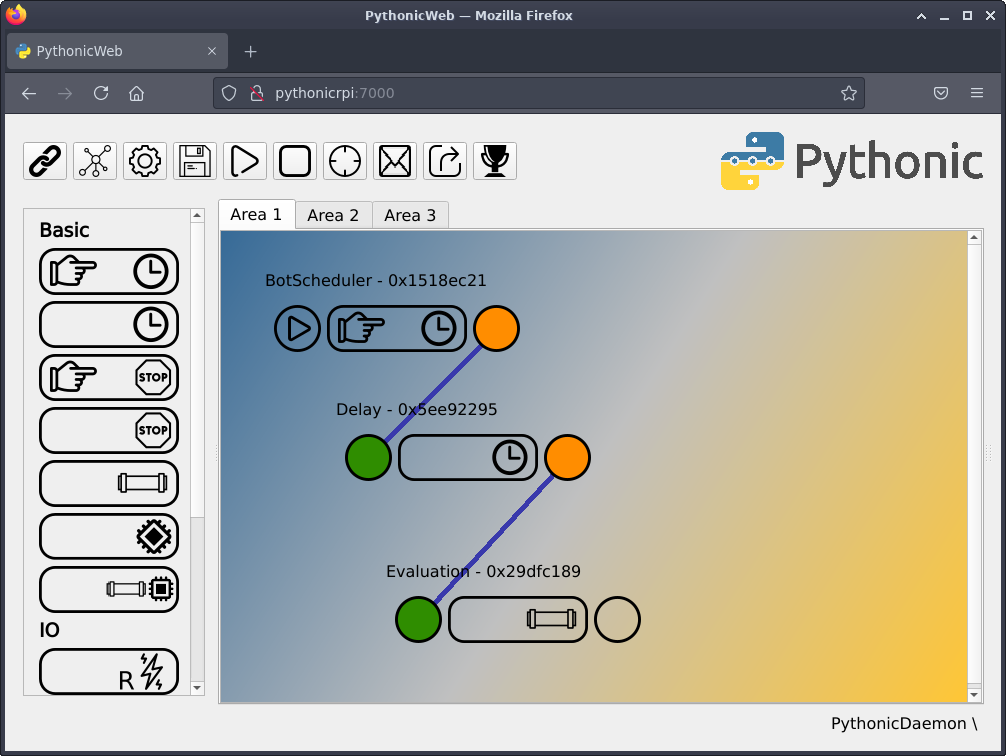
您可以在 Area 1 选项卡上找到决策的实施。

(Stephan Avenwedde, CC BY-SA 4.0)
它实现了以下功能
- BotScheduler:与 AcqusitionScheduler 相同:每五分钟触发后续元素
- 延迟:延迟执行 30 秒,以确保最新的 OHLCV 数据已写入文件
- 评估:基于 EMA 交叉策略做出交易决策
现在您已经了解了决策是如何进行的,您可以看看实际的实现。打开文件 generic_pipe_29dfc189.py。它对应于屏幕上的评估元素
@dataclass
class OrderRecord:
orderType: bool # True = Buy, False = Sell
price: float # close price
profit: float # profit in percent
profitCumulative: float # cumulative profit in percent
class OrderType(Enum):
Buy = True
Sell = False
class Element(Function):
def __init__(self, id, config, inputData, return_queue, cmd_queue):
super().__init__(id, config, inputData, return_queue, cmd_queue)
def execute(self):
### Load data ###
file_path = Path.home() / 'Pythonic' / 'executables' / 'ADAUSD_5m.df'
# only the last 21 columsn are considered
self.ohlcv = pd.read_pickle(file_path)[-21:]
self.bBought = False
self.lastPrice = 0.0
self.profit = 0.0
self.profitCumulative = 0.0
self.price = self.ohlcv['close'].iloc[-1]
# switches for simulation
self.bForceBuy = False
self.bForceSell = False
# load trade history from file
self.trackRecord = ListPersist('track_record')
try:
lastOrder = self.trackRecord[-1]
self.bBought = lastOrder.orderType
self.lastPrice = lastOrder.price
self.profitCumulative = lastOrder.profitCumulative
except IndexError:
pass
### Calculate indicators ###
self.ohlcv['ema-10'] = self.ohlcv['close'].ewm(span = 10, adjust=False).mean()
self.ohlcv['ema-21'] = self.ohlcv['close'].ewm(span = 21, adjust=False).mean()
self.ohlcv['condition'] = self.ohlcv['ema-10'] > self.ohlcv['ema-21']
### Check for Buy- / Sell-condition ###
tradeCondition = self.ohlcv['condition'].iloc[-1] != self.ohlcv['condition'].iloc[-2]
if tradeCondition or self.bForceBuy or self.bForceSell:
orderType = self.ohlcv['condition'].iloc[-1] # True = BUY, False = SELL
if orderType and not self.bBought or self.bForceBuy: # place a buy order
msg = 'Placing a Buy-order'
newOrder = self.createOrder(True)
elif not orderType and self.bBought or self.bForceSell: # place a sell order
msg = 'Placing a Sell-order'
sellPrice = self.price
buyPrice = self.lastPrice
self.profit = (sellPrice * 100) / buyPrice - 100
self.profitCumulative += self.profit
newOrder = self.createOrder(False)
else: # Something went wrong
msg = 'Warning: Condition for {}-order met but bBought is {}'.format(OrderType(orderType).name, self.bBought)
newOrder = None
recordDone = Record(newOrder, msg)
self.return_queue.put(recordDone)
def createOrder(self, orderType: bool) -> OrderRecord:
newOrder = OrderRecord(
orderType=orderType,
price=self.price,
profit=self.profit,
profitCumulative=self.profitCumulative
)
self.trackRecord.append(newOrder)
return newOrder由于总体的流程并不复杂,我想重点强调一些特殊之处
输入数据
交易机器人仅处理最后 21 个元素,因为这是您在计算指数移动平均线时考虑的范围
self.ohlcv = pd.read_pickle(file_path)[-21:]追踪记录
ListPersist 类型是一个扩展的 Python 列表对象,当它被修改时(当元素被添加或删除时)它会将自身写入文件系统。 第一次运行后,它会在 ~/Pythonic/executables/ 下创建文件 track_record.obj
self.trackRecord = ListPersist('track_record')维护追踪记录有助于保持最近机器人活动的状态。
合理性
如果满足交易条件,该算法会输出一个 OrderRecord 类型的对象。 它还会跟踪整体情况:例如,如果收到买入信号,但 bBought 表明您之前已经买入,则肯定出了问题
else: # Something went wrong
msg = 'Warning: Condition for {}-order met but bBought is {}'.format(OrderType(orderType).name, self.bBought)
newOrder = None在这种情况下,会返回 None 并附带相应的日志消息。
模拟
评估元素 (generic_pipe_29dfc189.py) 包含这些开关,使您可以强制执行买入或卖出订单
self.bForceBuy = False
self.bForceSell = False打开代码服务器 IDE (http : //PythonicRPI:8000/),加载 generic_pipe_29dfc189.py 并将其中一个开关设置为 True。附加调试器并在执行路径进入*内部 if* 条件的位置添加断点。

(Stephan Avenwedde, CC BY-SA 4.0)
现在打开编程 GUI,添加一个手动调度器元素(配置为*单次触发*)并将其直接连接到评估元素以手动触发它

(Stephan Avenwedde, CC BY-SA 4.0)
单击播放按钮。评估元素被直接触发,调试器在先前设置的断点处停止。 您现在能够手动添加、删除或修改追踪记录中的订单,以模拟某些场景

(Stephan Avenwedde, CC BY-SA 4.0)
打开日志消息窗口(绿色轮廓按钮)和输出数据窗口(橙色轮廓按钮)

(Stephan Avenwedde, CC BY-SA 4.0)
您将看到评估元素的日志消息和输出,从而了解基于您输入的决策算法的行为

(Stephan Avenwedde, CC BY-SA 4.0)
(Stephan Avenwedde, CC BY-SA 4.0)
总结
该示例在此处停止。 最终的实现可能会通知用户有关交易指示,在交易所下订单或提前查询帐户余额。 此时,您应该感觉到一切都已连接,并且能够自行进行操作了。
使用 Pythonic 作为您的交易机器人的基础是一个不错的选择,因为它可以在 Raspberry Pi 上运行,可以通过 Web 浏览器完全访问,并且已经具有日志记录功能。 即使使用 Pythonic 的多处理功能,也可以在断点处停止而不会干扰其他任务的执行。








评论已关闭。