

监督式机器学习的一大问题是需要大量的标记数据。尤其是在您没有标记数据的情况下,这是一个大问题——即使在当今大数据泛滥的世界中,我们大多数人也没有。
虽然少数公司可以访问大量特定类型的标记数据,但对于大多数组织和许多应用来说,创建足够数量的正确类型的标记数据成本过高或不可能实现。有时,领域本身就缺乏大量数据(例如,在诊断罕见疾病或确定签名是否与少数已知样本匹配时)。另一些时候,所需的数据量乘以 Amazon Turkers 或暑期实习生人工标记的成本就太高了。即使每帧只花一美分,为电影长度视频的每一帧贴标签也会迅速累积成本。
大数据需求的一大难题
我们小组着手解决的具体问题是:我们能否训练一个模型,在不手动绘制数百或数千个示例作为训练数据的情况下,自动将简单的配色方案应用于黑白角色?
在这个实验(我们称之为 DragonPaint)中,我们使用以下方法应对了深度学习对大量标记数据的需求问题:
- 一种基于规则的策略,用于对小型数据集进行极端扩充
- 借用 TensorFlow 图像到图像翻译模型 Pix2Pix,以在非常有限的训练数据下实现卡通着色自动化
我曾见过 Pix2Pix,这是一种机器学图像到图像翻译模型,在一篇论文(“Image-to-Image Translation with Conditional Adversarial Networks”,作者 Isola 等人)中描述过,它在 AB 对上训练后可以为风景着色,其中 A 是风景 B 的灰度版本。我的问题似乎类似。唯一的问题是训练数据。
我需要非常有限的训练数据,因为我不想为了训练模型而画一辈子卡通人物并为其着色。深度学习模型通常需要的数万(或数十万)个示例是不可能的。
根据 Pix2Pix 的示例,我们需要至少 400 到 1,000 个草图/彩色对。我愿意画多少个?也许 30 个。我画了几十朵卡通花和龙,并询问是否可以将其转化为训练集。
80% 的解决方案:按组件着色

opensource.com
当面临训练数据短缺时,首先要问的问题是,对于我们的问题,是否存在一种好的非机器学习方法。如果没有完整的解决方案,是否有部分解决方案,部分解决方案对我们有好处吗?我们甚至需要机器学习来为花和龙着色吗?还是我们可以指定几何规则来着色?

opensource.com
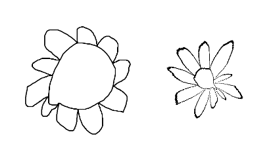
有一种非机器学习方法可以解决我的问题。我可以告诉孩子我希望如何为我的画作着色:将花朵的中心涂成橙色,花瓣涂成黄色。将龙的身体涂成橙色,尖刺涂成黄色。
起初,这似乎没有帮助,因为我们的计算机不知道什么是中心、花瓣、身体或尖刺。但事实证明,我们可以根据连通组件定义花朵或龙的部件,并获得几何解决方案,为我们约 80% 的画作着色。虽然 80% 还不够,但我们可以从基于规则的部分解决方案引导到 100%,方法是使用战略性的破规则转换、扩充和机器学习。
连通组件是您在使用 Windows 画图(或类似应用程序)时着色的内容。例如,在为二值黑白图像着色时,如果您单击白色像素,则无需跨越黑色即可到达的白色像素将被涂成新颜色。在“符合规则”的卡通龙或花朵草图中,最大的白色组件是背景。第二大是身体(加上手臂和腿)或花朵的中心。其余的是尖刺或花瓣,除了龙的眼睛,可以通过其与背景的距离来区分。
使用战略性破规则和 Pix2Pix 达到 100%
我的一些草图不符合规则。潦草绘制的线条可能会留下间隙。后肢会像尖刺一样被着色。一朵小的、居中的雏菊会交换花瓣和中心的着色规则。

opensource.com
对于我们无法使用几何规则着色的 20%,我们需要其他东西。我们转向 Pix2Pix,它需要至少 400 到 1,000 个草图/彩色对的最小训练集(即 Pix2Pix 论文中最小的训练集),包括破规则对。
因此,对于每个破规则示例,我们手动完成了着色(例如,后肢),或者取了一些守规则的草图/彩色对并打破了规则。我们在 A 中擦除了一点线条,或者我们使用相同的函数 (f) 转换了一对胖的、居中的花朵对 A 和 B,以创建一对新的 f(A) 和 f(B)——一朵小的、居中的花朵。这使我们得到了一个训练集。
使用高斯滤波器和同胚的极端扩充
在计算机视觉中,通常使用几何变换(例如旋转、平移和缩放)来扩充图像训练集。
但是,如果我们需要将向日葵变成雏菊,或者使龙的鼻子变得球状或尖状呢?
或者,如果我们只是需要在不发生过拟合的情况下大幅增加数据量呢?在这里,我们需要一个比我们开始时大 10 到 30 倍的数据集。
opensource.com
opensource.com
单位圆盘的某些同胚可以生成好的雏菊(例如,r -> r 的立方),而高斯滤波器可以改变龙的鼻子。两者对于为我们的数据集创建扩充非常有用,并产生了我们需要的扩充量,但它们也开始以仿射变换无法实现的方式改变绘图的风格。
这引发了关于如何自动化简单配色方案之外的问题:是什么定义了艺术家的风格,无论是对外部观看者还是对艺术家而言?艺术家何时将他们本不能在没有算法的情况下完成的绘画作品视为自己的作品?主题何时变得无法辨认?工具、助手和合作者之间有什么区别?
我们能走多远?
我们能画多少的输入,以及我们能在保持艺术家可识别的主题和风格的同时,创造多少变化和复杂性?我们需要做什么才能制作出源源不断的长颈鹿、龙或花朵?如果我们有一个,我们可以用它做什么?
这些是我们将在未来的工作中继续探索的问题。
但就目前而言,规则、扩充和 Pix2Pix 模型都奏效了。我们可以很好地为花朵着色,龙也不错。

opensource.com

opensource.com
要了解更多信息,请参加 Gretchen Greene 在 PyCon Cleveland 2018 上的演讲,DragonPaint – 使用少量数据引导卡通着色。




1 条评论