

我一直在为一个客户做一个数据抓取项目,并且在一些实验表明 Apache Tika 在从 PDF 文件中提取文本方面做得很好之后,开始使用它。本周,我遇到了 DBF 格式 的新数据源,结果证明 Tika 也能处理它。
受到这种令人愉悦的无缝体验的鼓舞,我决定是时候更多地了解 Tika 了。我发现自己在理解如何处理解码后的信息时遇到了一些困难。《Tika》网站和 Tika in Action 这本书都没有涵盖我需要的内容,我也无法在我最喜欢的搜索引擎上找到任何解决我试图解决的问题的内容。
因为 Tika 是开源的,所以我下载了源代码以获取一些工作示例并开始实验。这就是我最终完成我需要做的事情的方式——我希望有些人会觉得它有用。
在开始之前,我应该提到 Tika 是用 Java 编写的,而我的示例是用 Groovy 编写的。
问题
Tika 的架构由几个组件组成。特别感兴趣的是 Parser,它分解输入数据并将其转换为简单 XML API (SAX) 事件序列,以及 ContentHandler 接口,它将 SAX 信息交给程序员。
从我的角度来看(作为一个拥有各种格式数据的人),Tika 是那些出色的开源“平台”项目之一,它 鼓励其他开源项目的参与者 做出贡献(在这种情况下,使用解析器来解码信息),从而促进其共享和使用。并且 Tika 处理了大量的源格式(请参阅 git 页面,其中显示了它的 mimetypes.xml)。
在我的代码中使用 Tika 可以轻松解码表格文件格式,例如 DBF 或 XLS。但是,我找不到满足我需求的 content handler。Tika 提供的 content handlers 似乎分为两个主要类别:第一个按字段或作为一组文本行交付我的转换后的输入,字段由制表符分隔;第二个给我一个 XML/HTML 文档。这些都不真正符合我的需求。
例如,这个 LibreOffice 电子表格
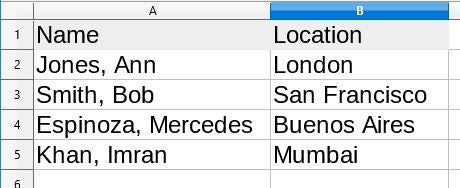
opensource.com
保存为 XLS 文件,然后由 BodyContentHandler 处理,输出如下所示
Sheet1
→ Name → Location
→ Jones, Ann → London
→ Smith, Bob → San Francisco
→ Espinoza, Mercedes → Buenos Aires
→ Khan, Imran → Mumbai
&C&"Times New Roman,Regular"&12&A
&C&"Times New Roman,Regular"&12Page &P其中 → 代表制表符。
当它由 ToXMLContentHandler 处理时,它的主体输出如下所示
<body><div class="page"><h1>Sheet1</h1>
<table><tbody><tr> <td>Name</td> <td>Location</td></tr>
<tr> <td>Jones, Ann</td> <td>London</td></tr>
<tr> <td>Smith, Bob</td> <td>San Francisco</td></tr>
<tr> <td>Espinoza, Mercedes</td> <td>Buenos Aires</td></tr>
<tr> <td>Khan, Imran</td> <td>Mumbai</td></tr>
</tbody></table>
<div class="outside">&C&"Times New Roman,Regular"&12&A</div>
<div class="outside">&C&"Times New Roman,Regular"&12Page &P</div>
</div>
</body>这些都不理想。我不喜欢使用制表符作为分隔符——如果我的某个字段包含制表符怎么办?——我也找不到一种方法将该字符设置为其他任何字符。至于 XML/HTML,对这段文本调用 XML 解析器,只是为了将其分解开来,这似乎非常奇怪。
当我仔细考虑这个问题并寻找自定义 content handler 的示例时,我注意到了两个关键的事情:首先,content handlers 特别是 SAX 通常与 Tika 分开,所以我开始在其他地方寻找有关它们的信息;其次,Tika 提供了(对我来说有点低调)自定义的完美起点:ContentHandlerDecorator。正如 ContentHandlerDecorator API 页面指出的那样,“子类可以通过覆盖一个或多个 SAX 事件方法来提供额外的装饰。”(有关 decorator 的更多信息,请阅读 Wikipedia 上关于 装饰器模式 的文章。)
ContentHandlerDecorator 能否为我提供一种将 SAX 事件序列转换为我需要的内容的好方法,而无需太多额外的花哨操作?
解决方案
基本上,我想要一种生成哈希表列表的方法,其中每个哈希表对应于表格数据中的一行,键设置为列名,值设置为相应行和列中的单元格内容。在 Groovy 中,我的电子表格以这种方式呈现,将被声明为
def data = [
[Name: 'Jones, Ann', Location: 'London'],
[Name: 'Smith, Bob', Location: 'San Francisco'],
[Name: 'Espinoza, Mercedes', Location: 'Buenos Aires'],
[Name: 'Khan, Imran', Location: 'Mumbai']
]我仔细阅读了 Tika 的各种 content handlers 的源代码,我了解到我可以通过覆盖 ContentHandlerDecorator 中的三个方法来实现我的目标
- startElement() 方法将在每个 HTML 元素的开头被调用,例如 <TABLE>、<TR>、<TD>,在每个文档元素的开头;
- endElement() 方法将在每个 HTML 元素的末尾被调用,例如 </TABLE>、</TR>、</TD>,在每个文档元素的末尾;以及
- characters() 方法将在需要写出文本时被调用。
我需要实现这些方法来
- 决定何时保存发送到 characters() 的文本;
- 使用 startElement() 监视 <TD> 并打开文本保存;
- 使用 endElement() 监视 </TD> 并关闭文本保存;
- 使用 startElement() 监视 <TR> 并创建一个空列表以保存行数据;
- 使用 endElement() 监视 </TR> 并将行数据列表转换为 map,并将该 map 添加到行 map 列表中;哦,对了,
- 使用 endElement() 将第一行视为标题而不是数据,并将其保存到标题列表而不是行数据。
简单!让我们编写一些代码!
首先,在 Groovy 中,我创建了一个 ContentHandlerDecorator,如下所示
def handler = new ContentHandlerDecorator() {
// we know we need a row counter and a list of row maps
int rowCount = 0
def rowMapList = []
// we also know we need a list of column names and row values
def columnNameList = []
def rowValueList
// we know we want to give the user access to rowMapList[]
public def getRowMapList() {
rowMapList
}
// we may as well offer a String version of rowMapList[]
@Override
public String toString() {
rowMapList.toString()
}
// rest of the code goes in here
}接下来,我需要保存感兴趣的文本
boolean inDataElement = false
StringBuffer dataElement
@Override
public void characters(char[] ch, int start, int length) {
if (inDataElement)
dataElement.append(ch, start, length)
}我使用了 StringBuffer,它本质上是一个可变字符串。它似乎非常适合 characters() 的参数。此代码遵循前一个代码块中的注释“其余代码放在这里”。
接下来,我需要处理数据元素和行的结尾
@Override
void endElement(String uri, String localName, String name) {
switch (name) {
case 'td':
inDataElement = false
if (rowCount == 0)
columnNameList.add(dataElement.toString())
else
rowValueList.add(dataElement.toString())
break
case 'tr':
if (rowCount > 0)
rowMapList.
add([columnNameList, rowValueList].
transpose().
collectEntries { e ->
[(e[0]): (e[1].trim())]
})
rowCount++
break
default: break
}
}此代码片段紧跟在前一个代码片段之后。它包含很好的经验——以及一些非常 groovy 的 Groovy 代码——因此值得详细了解一下
- 在测试 SAX 事件序列的工作方式时,我确定我实际上只需要查看开始和结束元素的 name 参数。
- 我正在使用 Groovy 在字符串值上进行 switch () { … } 的能力来获取 </TR> 和 </TD> 元素。
- 当我遇到 </TD> 时,我知道刚刚处理的数据元素如果是在第一条记录上,将进入列名列表,否则将进入行值列表。
- 当我遇到 </TR> 时,我知道如果我在第二行或后续行,我需要将列名列表和行值列表转换为我的行 map。
- 我使用 transpose() 在列表中交错排列列名/行值对。
- 然后我使用 collectEntries() 将列名和行值对转换为 map 条目。
- 我记得更新行数!
最后,我将其设置为处理数据元素和行的开始
@Override
void startElement(String uri, String localName, String name,
org.xml.sax.Attributes atts) {
switch (name) {
case 'tr':
if (rowCount > 0)
rowValueList = []
break
case 'td':
inDataElement = true
dataElement = new StringBuffer()
break
default: break
}
}这查找 <TR> 以(重新)初始化行值列表,并查找 <TD> 以注意它正在处理有用的数据元素,并且是时候将传递给 helper 的字符保存在新的字符串缓冲区中了。再次,此代码紧随前一个代码之后。
就是这样!要使用此代码,请运行类似以下内容
import org.apache.tika.*
import org.apache.tika.parser.*
import org.apache.tika.metadata.*
import org.apache.tika.sax.*
// define the file we’re reading and get an input stream
// based on that file
def file = new File('test.xls')
def fis = new FileInputStream(file)
// define the metadata and parser
def metadata = new Metadata()
def parser = new AutoDetectParser()
// define the content handler (copy the code created above)
def handler = new ContentHandlerDecorator() {
// …
};
// parse the input file
parser.parse(fis, handler, metadata)
// here we visit all the elements in the row map list
// and print out each row map, one per line
handler.rowMapList.each { map ->
println map
}
fis.close()以获得此输出
[Name:Jones, Ann, Location:London]
[Name:Smith, Bob, Location:San Francisco]
[Name:Espinoza, Mercedes, Location:Buenos Aires]
[Name:Khan, Imran, Location:Mumbai]正是医生开的药!
所以现在,代替 handler.rowMapList.each { map -> … } 闭包,我可以研究每个单元格值。例如
if (map.Name == ‘Smith, Bob’)
map.Location = ‘Nairobi’当我想将 Bob Smith 从伦敦搬到内罗毕,或者
new Employee(name: map.Name, location: map.Location).save()当我想将数据插入到我的 Grails 数据库中时。
正如我所发现的,Tika Parser 非常擅长解析事物,但 ContentHandler 接口是将其以有用的方式重新组合在一起的关键。





评论已关闭。