

基础设施环境的需求每年都在变化,系统变得更加复杂和深入。但是,如果我们不了解基础设施以及我们环境中发生的事情,所有这些增长都毫无意义。这就是监控工具和软件的用武之地;它们使操作员和管理员能够看到他们环境中的问题并实时修复它们。
但是,如果我们想在问题发生之前预测问题呢?收集有关我们环境的指标和数据,可以让我们了解我们基础设施的运行状况,并让我们根据数据进行预测。当我们知道并了解正在发生的事情时,我们可以预防问题,而不是仅仅修复问题。
在我们使用这些数据之前,我们需要弄清楚如何收集和存储它。例如,如果我们想每 10 秒收集 100 台机器的 CPU 使用率数据,我们将生成大量数据。最重要的是,如果每台机器运行 15 个容器,并且您也想生成有关每个单独容器的数据,该怎么办?如果我们想按进程生成数据呢?这就是时序数据变得有用的地方。时序数据库存储时序数据。但这到底意味着什么?我们将解释所有这些以及更多内容,并向您介绍 InfluxDB,一个开源时序数据库。在本文结束时,您将了解
- 什么是时序数据和数据库
- 关于 InfluxDB 和 TICK 栈的基本信息
- 如何安装 InfluxDB 和其他工具
时序概念介绍

opensource.com
如果您熟悉关系数据库管理软件 (RDBMS),例如 MySQL,那么 表、列和主键 是熟悉的术语。一切都像电子表格,数据在列和行中。有些数据可能是唯一的,其他部分可能与其他行相同。关系数据库被广泛使用,非常适合遵循 ACID(原子性、一致性、隔离性和持久性)合规性的可靠事务以及您可以在表中建模的数据。您可以通过覆盖和替换来更新某些数据。
但是,如果您正在收集有关生成大量数据的事物(例如自动驾驶汽车)的数据,并且您想观察数据如何随时间变化,该怎么办?汽车不断收集有关其环境的信息。它获取这些数据并分析随时间的变化以正确运行。数据量可能达到每小时数十 GB。虽然您可以使用关系数据库来收集这些数据,但当涉及到您正在收集的数据的可扩展性和可用性时,RBDMS 并不是完成这项工作的最佳工具。
为什么时序是一个不错的选择
这就是时序数据有意义的地方。假设您正在收集有关城市交通、农业设备温度或装配线生产率的数据。与其将数据放入带有行和列的表中,不如想象一下推送多行数据,这些数据通过时间戳进行唯一排序。这种可视化可能有助于更好地理解这一点
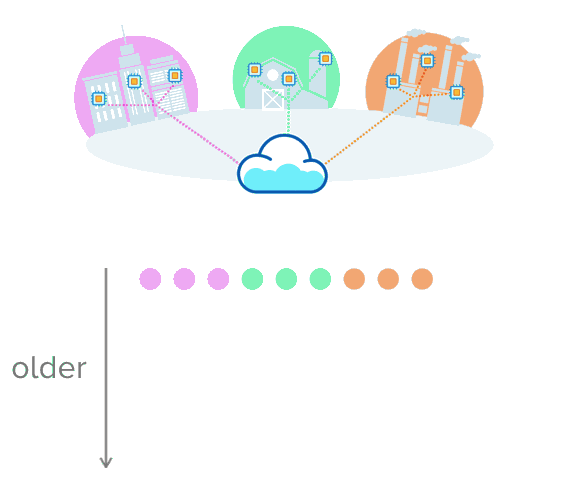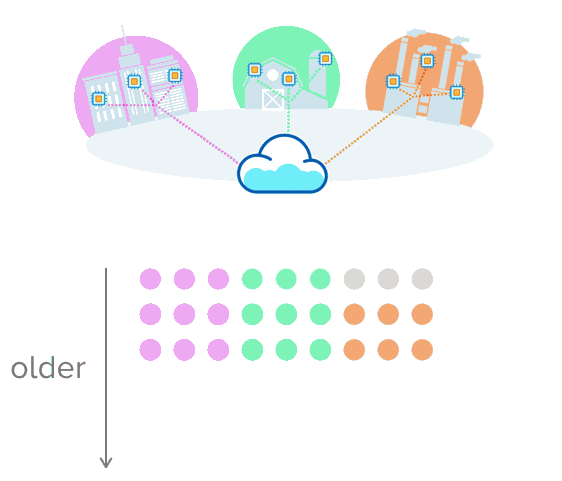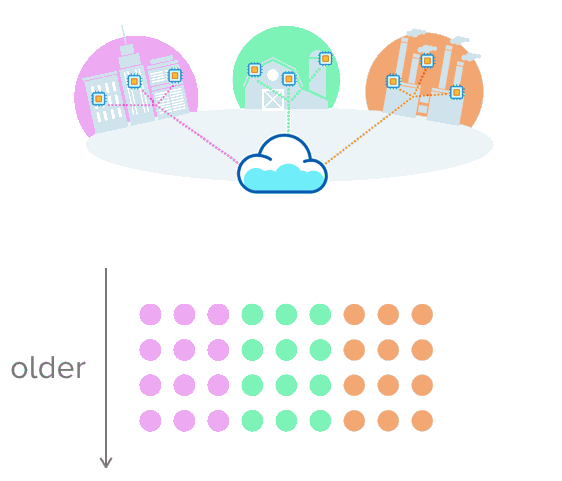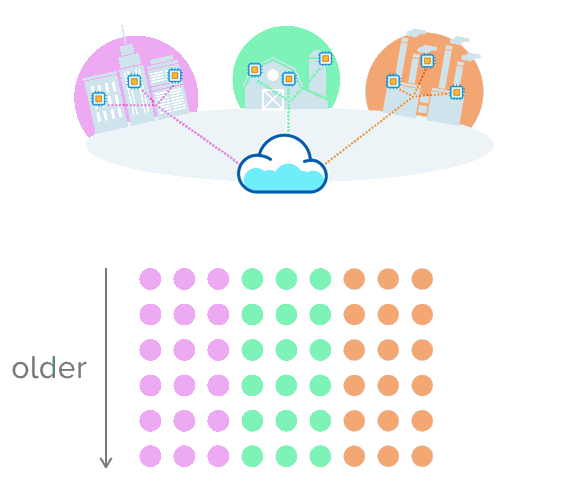
opensource.com
以这种格式存储数据可以更轻松地跟踪和观察随时间的变化。当数据累积时,您可以看到某事物过去的行为方式、现在的行为方式以及未来可能的行为方式。您做出更明智的数据决策的选择会扩大!
好奇数据是如何存储和格式化的吗?这取决于您使用的时序数据库。 InfluxDB 以 Line Protocol 格式存储数据。查询 以 JSON 格式返回数据。
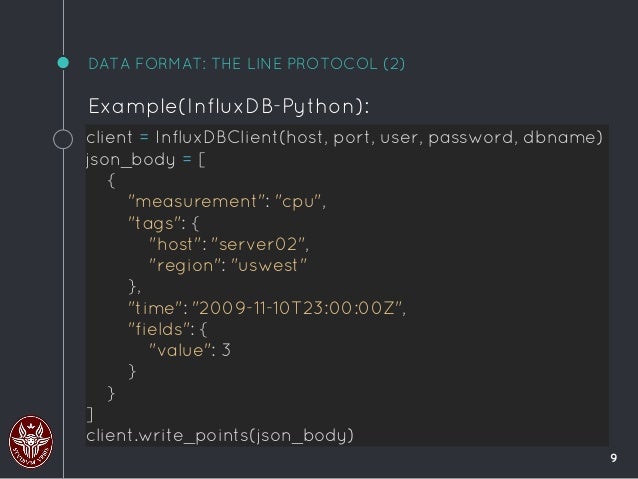
opensource.com
要了解有关时序数据的更多信息,或了解为什么您想使用它而不是其他解决方案,Timescale 和 InfluxData 提供了出色的、深入的解释。
InfluxDB:一个时序数据库
InfluxDB 是由 InfluxData 开发的开源时序数据库软件。它用 Go(一种编译语言)编写,这意味着您可以开始使用它,而无需安装任何依赖项。它支持多种数据摄取协议,例如 Telegraf(也来自 InfluxData)、Graphite、Collectd 和 OpenTSDB。这为您提供了灵活的选项,可用于如何收集数据以及从何处提取数据。它也是可用的 增长最快 的时序数据库软件选项之一。您可以在 GitHub 上找到 InfluxDB 的源代码。
让我们看看如何使用 InfluxData 的 TICK 栈 中的三个工具来构建时序数据库,并开始收集和处理数据。
TICK 栈
InfluxData 的平台基于四个开源项目,这些项目可以很好地协同工作,用于时序数据。通过将它们一起使用,您可以轻松地收集、存储、处理和查看数据。该平台的四个部分被称为 TICK 栈,它代表
- Telegraf:插件驱动的服务器代理,用于收集和报告指标
- InfluxDB:用于指标、事件和实时分析的可扩展数据存储
- Chronograf:用于 TICK 栈的监控/可视化用户界面(本文未涵盖)
- Kapacitor:用于处理、监控和警报时序数据的框架
这些工具通过设计可以很好地协同工作并与其他部分集成。但是,也很容易用您选择的另一个工具替换一个部分。在这里,我们将探讨 TICK 栈的三个部分:InfluxDB、Telegraf 和 Kapacitor。
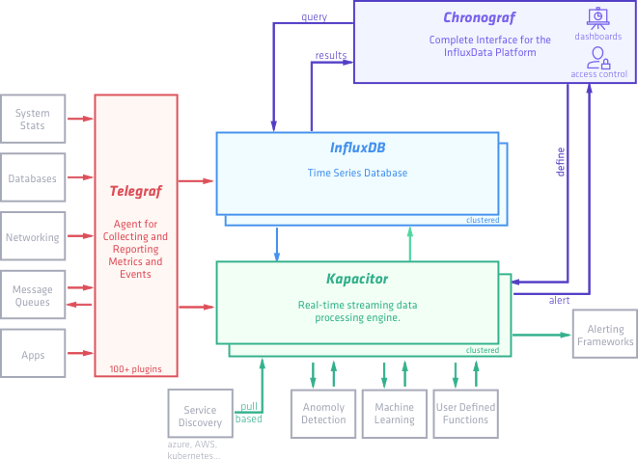
opensource.com
InfluxDB
如前所述,InfluxDB 是 TICK 栈的时序数据库。有一些因素使 InfluxDB 从其他时序数据库中脱颖而出。
- 强调性能: 性能是 InfluxDB 的首要任务之一。这使您可以快速轻松地使用数据,即使在高负载下也是如此。为此,InfluxDB 专注于快速摄取数据并使用压缩来保持其可管理性。为了查询和写入数据,它使用 HTTP(S) API。它的性能值得注意,体现了 InfluxDB 能够处理的数据量。它可以处理每秒高达一百万个数据点,精度很高,甚至达到纳秒级。
- 类似 SQL 的查询: 如果您熟悉类似 SQL 的语法,那么从 InfluxDB 查询数据会感到很熟悉。它使用自己的类似 SQL 的语法 InfluxQL 进行查询。例如,假设您正在收集有关机器上已用磁盘空间的数据。如果您想查看该数据,您可以编写一个查询,该查询可能如下所示,它将从三个月的时间段中提取已用磁盘空间的平均值,并将它们以 10 天为增量进行分组
SELECT mean(diskspace_used) as mean_disk_used
FROM disk_stats
WHERE time() >= 3m
GROUP BY time(10d)- 降采样和数据保留: 当处理大量数据时,存储数据成为一个问题。随着时间的推移,它会累积到巨大的尺寸。使用 InfluxDB,您可以降采样为不太精确、更小的指标,您可以将这些指标存储更长的时间。数据保留策略使您能够做到这一点。例如,假设您有传感器收集有关多台机器中 RAM 量的数据。您可能会收集有关多个用户、系统、缓存内存等使用的内存量的指标。虽然保留这些数据 30 天以观察正在发生的事情可能是有意义的,但在 30 天后,您可能不需要如此精确的数据。相反,您可能只需要总内存与已用内存的比率。使用数据保留策略,您可以告诉 InfluxDB 保留所有不同用途的精确数据 30 天。30 天后,您可以平均数据以降低精度,并且您可以将该数据保存六个月、永久或您喜欢的任何时间。这种折衷方案在保留历史数据和减少磁盘使用之间取得了平衡。
Telegraf
如果 InfluxDB 是您所有数据的去向,那么您首先需要一种收集和获取数据的方法。Telegraf 是一个指标收集守护程序,它从系统组件、物联网 (IoT) 传感器等收集各种指标。它是 开源 的,并且完全用 Go 编写。与 InfluxDB 一样,Telegraf 由 InfluxData 团队编写,并且它旨在与 InfluxDB 协同工作。它还包括对不同数据库(例如 MySQL/MariaDB、MongoDB、Redis 等)的支持。您可以在 InfluxData 的网站上阅读有关它的更多信息。
Telegraf 是模块化的,并且在很大程度上基于插件。这意味着 Telegraf 可以根据您的需要变得精简和最小化,或者变得完整和复杂。开箱即用,它支持 100 多个用于各种输入源(包括 Apache、Ceph、Docker、Iptables、Kubernetes、Nginx 和 Varnish)、处理和输出的 插件。
即使您不使用 InfluxDB 作为数据存储,您也可能会发现 Telegraf 是一种收集有关您的系统或传感器的数据和信息的有用方法。
Kapacitor
现在我们有了一种收集和存储数据的方法。但是如何使用它做事情呢? Kapacitor 是堆栈的一部分,可让您以几种不同的方式处理和使用数据。它支持流数据和批处理数据。流数据意味着您可以主动实时地处理和塑造数据,甚至在数据到达数据存储之前。批处理数据意味着您可以追溯地对数据样本或批次执行操作。
Kapacitor 最大的优点之一是它能够为您的环境中发生的事件启用实时警报。CPU 使用率过高或温度过高?您可以设置几个不同的警报系统,包括但不限于电子邮件、触发命令、Slack、HipChat、OpsGenie 等等。您可以在 文档 中查看完整列表。
与其他 TICK 栈工具一样,Kapacitor 是 开源 的;您可以在 README 中阅读有关该项目的更多信息。
安装 TICK 栈
几乎每个发行版都有软件包可用。您可以从命令行安装这些软件包。使用适合您发行版的说明。
Fedora
sudo dnf install https://dl.influxdata.com/influxdb/releases/influxdb-1.3.1.x86_64.rpm \
https://dl.influxdata.com/telegraf/releases/telegraf-1.3.4-1.x86_64.rpm \
https://dl.influxdata.com/kapacitor/releases/kapacitor-1.3.1.x86_64.rpmCentOS 7/RHEL 7
sudo yum install https://dl.influxdata.com/influxdb/releases/influxdb-1.3.1.x86_64.rpm \
https://dl.influxdata.com/telegraf/releases/telegraf-1.3.4-1.x86_64.rpm \
https://dl.influxdata.com/kapacitor/releases/kapacitor-1.3.1.x86_64.rpmUbuntu/Debian
wget https://dl.influxdata.com/influxdb/releases/influxdb_1.3.1_amd64.deb \
https://dl.influxdata.com/telegraf/releases/telegraf_1.3.4-1_amd64.deb \
https://dl.influxdata.com/kapacitor/releases/kapacitor_1.3.1_amd64.deb
sudo dpkg -i influxdb_1.3.1_amd64.deb telegraf_1.3.4-1_amd64.deb kapacitor_1.3.1_amd64.deb其他发行版
如需其他发行版的帮助,请参阅 下载 页面。
查看数据,成为数据
现在您已经安装了这些工具,您可以尝试其中的一些工具。所有这三个项目都有大量的上游文档
此外,如需更多帮助,您可以访问 InfluxData 社区论坛。祝您编程愉快!





评论已关闭。